Chapter 0: Introduction and Aggregation Concepts
Introduction to the MongoDB Aggregation Framework
Chapter 0: Introduction and Aggregation Concepts
Atlas Requirement
mongo "mongodb://cluster0-shard-00-00-jxeqq.mongodb.net:27017,cluster0-shard-00-01-jxeqq.mongodb.net:27017,cluster0-shard-00-02-jxeqq.mongodb.net:27017/aggregations?replicaSet=Cluster0-shard-0" --authenticationDatabase admin --ssl -u m121 -p aggregations --norc
Cluster0-shard-0:PRIMARY> show collections
air_airlines
air_alliances
air_routes
bronze_banking
customers
employees
exoplanets
gold_banking
icecream_data
movies
nycFacilities
silver_banking
solarSystem
stocks
system.views
mongosh "mongodb://cluster0-shard-00-00-jxeqq.mongodb.net:27017,cluster0-shard-00-01-jxeqq.mongodb.net:27017,cluster0-shard-00-02-jxeqq.mongodb.net:27017/aggregations?replicaSet=Cluster0-shard-0" --authenticationDatabase admin --ssl -u m121 -p aggregations --norc
Chapter 0: Introduction and Aggregation Concepts
The Concept of Pipelines
Which of the following is true about pipelines and the Aggregation Framework?
- Documents flow through the pipeline, passing from one stage to the next
- The Aggregation Framework provides us many stages to filter and transform our data
Chapter 0: Introduction and Aggregation Concepts
Aggregation Structure and Syntax
https://www.mongodb.com/docs/manual/meta/aggregation-quick-reference/
Aggregation Pipeline Quick Reference — MongoDB Manual
Docs Home → MongoDB ManualFor details on specific operator, including syntax and examples, click on the specific operator to go to its reference page.In the db.collection.aggregate() method, pipeline stages appear in an array. Documents pass through the
www.mongodb.com
Which of the following statements is true?
- An aggregation pipeline is an array of stages.
- Some expressions can only be used in certain stages.
Chapter 1: Basic Aggregation - $match and $project
$match: Filtering documents
https://www.mongodb.com/docs/manual/reference/operator/aggregation/match/?jmp=university
$match (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$matchFilters the documents to pass only the documents that match the specified condition(s) to the next pipeline stage.The $match stage has the following prototype form:$match takes a document that specifies the query condition
www.mongodb.com
Which of the following is/are true of the $match stage?
- It should come very early in an aggregation pipeline.
- It uses the familiar MongoDB query language.
Chapter 1: Basic Aggregation - $match and $project
Lab - $match
mongo "mongodb://cluster0-shard-00-00-jxeqq.mongodb.net:27017,cluster0-shard-00-01-jxeqq.mongodb.net:27017,cluster0-shard-00-02-jxeqq.mongodb.net:27017/aggregations?replicaSet=Cluster0-shard-0" --authenticationDatabase admin --ssl -u m121 -p aggregations --norc
db
mongosh "mongodb://cluster0-shard-00-00-jxeqq.mongodb.net:27017,cluster0-shard-00-01-jxeqq.mongodb.net:27017,cluster0-shard-00-02-jxeqq.mongodb.net:27017/aggregations?replicaSet=Cluster0-shard-0" --authenticationDatabase admin --ssl -u m121 -p aggregations --norc
Help MongoDB pick a movie our next movie night! Based on employee polling, we've decided that potential movies must meet the following criteria.
- imdb.rating is at least 7
- genres does not contain "Crime" or "Horror"
- rated is either "PG" or "G"
- languages contains "English" and "Japanese"
Assign the aggregation to a variable named pipeline, like:
var pipeline = [ { $match: { ... } } ]
- As a hint, your aggregation should return 23 documents. You can verify this by typing db.movies.aggregate(pipeline).itcount()
- Download the m121/chapter1.zip handout with this lab. Unzip the downloaded folder and copy its contents to the m121 directory.
- Load validateLab1.js into mongo shell
load('validateLab1.js')
- And run the validateLab1 validation method
validateLab1(pipeline)
What is the answer?

-> 15
Chapter 1: Basic Aggregation - $match and $project
Shaping documents with $project
https://www.mongodb.com/docs/manual/reference/operator/aggregation/project/?jmp=university
$project (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$projectPasses along the documents with the requested fields to the next stage in the pipeline. The specified fields can be existing fields from the input documents or newly computed fields.The $project stage has the following p
www.mongodb.com
Which of the following statements are true of the $project stage?
- Once we specify a field to retain or perform some computation in a $project stage, we must specify all fields we wish to retain. The only exception to this is the _id field.
- Beyond simply removing and retaining fields, $project lets us add new fields.
Our first movie night was a success. Unfortunately, our ISP called to let us know we're close to our bandwidth quota, but we need another movie recommendation!
Using the same $match stage from the previous lab, add a $project stage to only display the title and film rating (title and rated fields).
- Assign the results to a variable called pipeline.
var pipeline = [{ $match: {. . .} }, { $project: { . . . } }]
- Load validateLab2.js which was included in the same handout as validateLab1.js and execute validateLab2(pipeline)?
load('./validateLab2.js')
- And run the validateLab2 validation method
validateLab2(pipeline)
What is the answer?

-> 15
Chapter 1: Basic Aggregation - $match and $project
Lab - Computing Fields
Our movies dataset has a lot of different documents, some with more convoluted titles than others. If we'd like to analyze our collection to find movie titles that are composed of only one word, we could fetch all the movies in the dataset and do some processing in a client application, but the Aggregation Framework allows us to do this on the server!
Using the Aggregation Framework, find a count of the number of movies that have a title composed of one word. To clarify, "Cinderella" and "3-25" should count, where as "Cast Away" would not.
Make sure you look into the $split String expression and the $size Array expression
To get the count, you can append itcount() to the end of your pipeline
db.movies.aggregate([...]).itcount()

-> 8066
Chapter 1: Basic Aggregation - $match and $project
Optional Lab - Expressions with $project
This lab will have you work with data within arrays, a common operation.
Specifically, one of the arrays you'll work with is writers, from the movies collection.
There are times when we want to make sure that the field is an array, and that it is not empty. We can do this within $match
{ $match: { writers: { $elemMatch: { $exists: true } } }
However, the entries within writers presents another problem. A good amount of entries in writers look something like the following, where the writer is attributed with their specific contribution
"writers" : [ "Vincenzo Cerami (story)", "Roberto Benigni (story)" ]
But the writer also appears in the cast array as "Roberto Benigni"!
Give it a look with the following query
db.movies.findOne({title: "Life Is Beautiful"}, { _id: 0, cast: 1, writers: 1})
This presents a problem, since comparing "Roberto Benigni" to "Roberto Benigni (story)" will definitely result in a difference.
Thankfully there is a powerful expression to help us, $map. $map lets us iterate over an array, element by element, performing some transformation on each element. The result of that transformation will be returned in the same place as the original element.
Within $map, the argument to input can be any expression as long as it resolves to an array. The argument to as is the name of the variable we want to use to refer to each element of the array when performing whatever logic we want. The field as is optional, and if omitted each element must be referred to as $$this:: The argument to in is the expression that is applied to each element of the input array, referenced with the variable name specified in as, and prepending two dollar signs:
writers: {
$map: {
input: "$writers",
as: "writer",
in: "$$writer"
}
}
in is where the work is performed. Here, we use the $arrayElemAt expression, which takes two arguments, the array and the index of the element we want. We use the $split expression, splitting the values on " (".
If the string did not contain the pattern specified, the only modification is it is wrapped in an array, so $arrayElemAt will always work
writers: {
$map: {
input: "$writers",
as: "writer",
in: {
$arrayElemAt: [
{
$split: [ "$$writer", " (" ]
},
0
]
}
}
}
Let's find how many movies in our movies collection are a "labor of love", where the same person appears in cast, directors, and writers
Hint: You will need to use $setIntersection operator in the aggregation pipeline to find out the result.
Note that your dataset may have duplicate entries for some films. You do not need to count the duplicate entries.
To get a count after you have defined your pipeline, there are two simple methods.
// add the $count stage to the end of your pipeline
// you will learn about this stage shortly!
db.movies.aggregate([
{$stage1},
{$stage2},
{...$stageN},
{ $count: "labors of love" }
])
// or use itcount()
db.movies.aggregate([
{$stage1},
{$stage2},
{...$stageN}
]).itcount()
How many movies are "labors of love"?
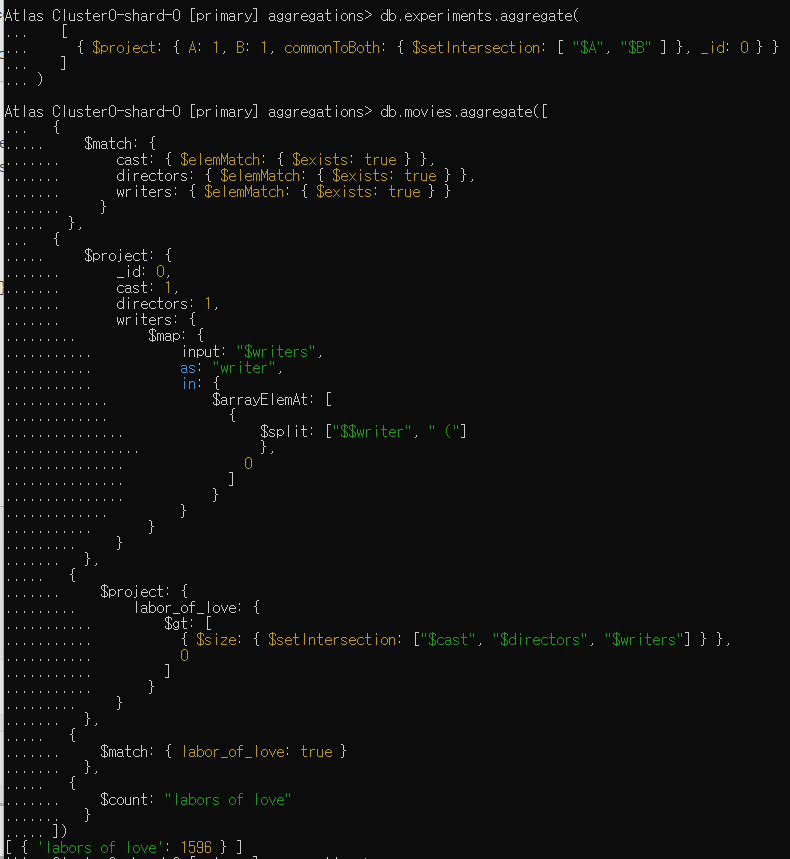
-> 1596
Chapter 2: Basic Aggregation - Utility Stages
$addFields and how it is similar to $project
https://www.mongodb.com/docs/manual/reference/operator/aggregation/addFields/?jmp=university
$addFields (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$addFieldsAdds new fields to documents. $addFields outputs documents that contain all existing fields from the input documents and newly added fields.The $addFields stage is equivalent to a $project stage that explicitly specifi
www.mongodb.com
Chapter 2: Basic Aggregation - Utility Stages
geoNear Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/geoNear/?jmp=university
$geoNear (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$geoNearOutputs documents in order of nearest to farthest from a specified point.Starting in version 4.2, MongoDB removes the limit and num options for the $geoNear stage as well as the default limit of 100 documents. To limit t
www.mongodb.com
Chapter 2: Basic Aggregation - Utility Stages
Cursor-like stages: Part 1
Chapter 2: Basic Aggregation - Utility Stages
Cursor-like stages: Part 2
Chapter 2: Basic Aggregation - Utility Stages
$sample Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/sample/?jmp=university
$sample (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$sampleRandomly selects the specified number of documents from the input documents.The $sample stage has the following syntax:{ $sample: { size: } }N is the number of documents to randomly select.If all of the following conditio
www.mongodb.com
Chapter 2: Basic Aggregation - Utility Stages
Lab: Using Cursor-like Stages
MongoDB has another movie night scheduled. This time, we polled employees for their favorite actress or actor, and got these results
favorites = [
"Sandra Bullock",
"Tom Hanks",
"Julia Roberts",
"Kevin Spacey",
"George Clooney"]
For movies released in the USA with a tomatoes.viewer.rating greater than or equal to 3, calculate a new field called num_favs that represets how many favorites appear in the cast field of the movie.
Sort your results by num_favs, tomatoes.viewer.rating, and title, all in descending order.
What is the title of the 25th film in the aggregation result?
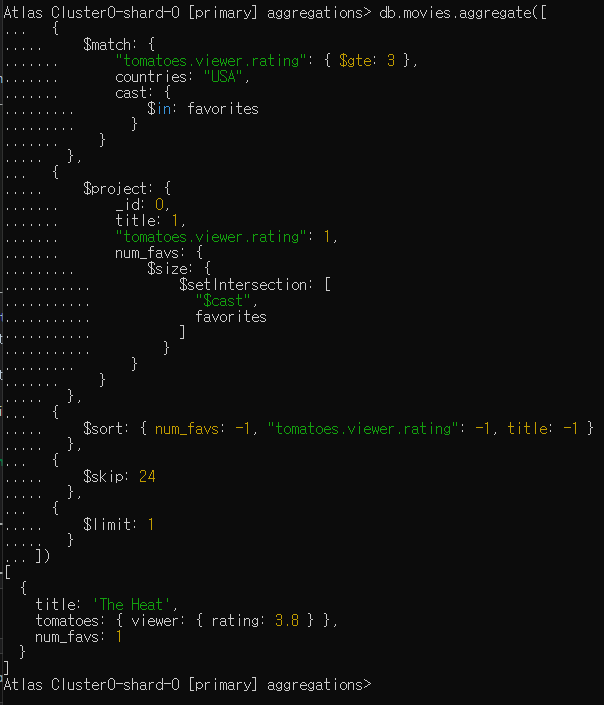
-> The Heat
Chapter 2: Basic Aggregation - Utility Stages
Lab - Bringing it all together
Calculate an average rating for each movie in our collection where English is an available language, the minimum imdb.rating is at least 1, the minimum imdb.votes is at least 1, and it was released in 1990 or after. You'll be required to rescale (or normalize) imdb.votes. The formula to rescale imdb.votes and calculate normalized_rating is included as a handout.
What film has the lowest normalized_rating?
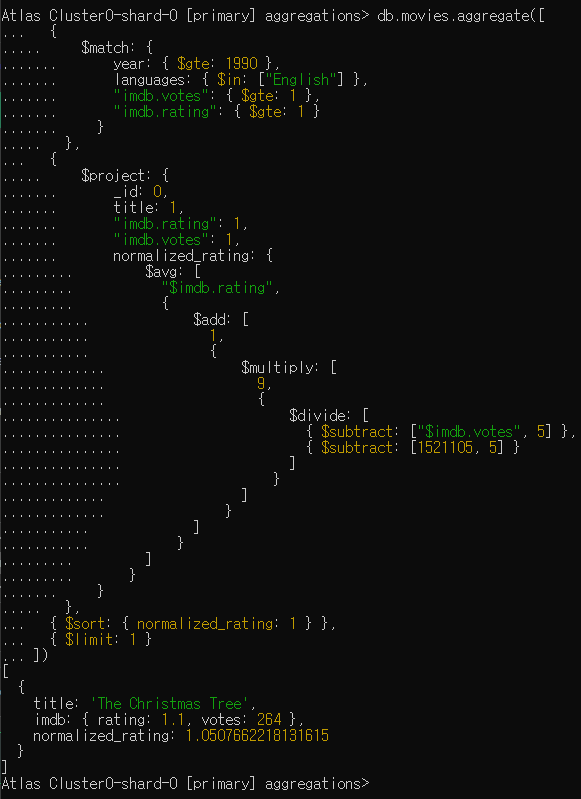
-> The Christmas Tree
Chapter 3: Core Aggregation - Combining Information
The $group Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/group/?jmp=university
$group (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$groupGroups input documents by the specified _id expression and for each distinct grouping, outputs a document. The _id field of each output document contains the unique group by value. The output documents can also contain com
www.mongodb.com
Chapter 3: Core Aggregation - Combining Information
Accumulator Stages with $project
https://www.mongodb.com/docs/manual/reference/operator/aggregation/#group-accumulator-operators
Aggregation Pipeline Operators — MongoDB Manual
Docs Home → MongoDB ManualFor details on specific operator, including syntax and examples, click on the specific operator to go to its reference page.These expression operators are available to construct expressions for use in the aggregation pipeline st
www.mongodb.com
Chapter 3: Core Aggregation - Combining Information
Lab - $group and Accumulators
In the last lab, we calculated a normalized rating that required us to know what the minimum and maximum values for imdb.votes were. These values were found using the $group stage!
For all films that won at least 1 Oscar, calculate the standard deviation, highest, lowest, and average imdb.rating. Use the sample standard deviation expression.
HINT - All movies in the collection that won an Oscar begin with a string resembling one of the following in their awards field
Won 13 Oscars
Won 1 Oscar
Select the correct answer from the choices below. Numbers are truncated to 4 decimal places.

-> { "highest_rating" : 9.2, "lowest_rating" : 4.5, "average_rating" : 7.5270, "deviation" : 0.5988 }
Chapter 3: Core Aggregation - Combining Information
The $unwind Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/unwind/
$unwind (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$unwindDeconstructs an array field from the input documents to output a document for each element. Each output document is the input document with the value of the array field replaced by the element.You can pass a field path op
www.mongodb.com
Chapter 3: Core Aggregation - Combining Information
Lab - $unwind
Let's use our increasing knowledge of the Aggregation Framework to explore our movies collection in more detail. We'd like to calculate how many movies every cast member has been in and get an average imdb.rating for each cast member.
What is the name, number of movies, and average rating (truncated to one decimal) for the cast member that has been in the most number of movies with English as an available language?
Provide the input in the following order and format
{ "_id": "First Last", "numFilms": 1, "average": 1.1 }

Chapter 3: Core Aggregation - Combining Information
The $lookup Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/lookup/
$lookup (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$lookupPerforms a left outer join to an unsharded collection in the same database to filter in documents from the "joined" collection for processing. To each input document, the $lookup stage adds a new array field whose element
www.mongodb.com
Chapter 3: Core Aggregation - Combining Information
The $lookup Stage
Which of the following statements is true about the $lookup stage?
- $lookup matches between localField and foreignField with an equality match
- The collection specified in from cannot be sharded
- Specifying an existing field name to as will overwrite the the existing field
Chapter 3: Core Aggregation - Combining Information
Lab - Using $lookup
Which alliance from air_alliances flies the most routes with either a Boeing 747 or an Airbus A380 (abbreviated 747 and 380 in air_routes)?

Chapter 3: Core Aggregation - Combining Information
$graphLookup Introduction
Which of the following statements apply to $graphLookup operator? check all that apply
-> $graphLookup provides MongoDB a transitive closure implementation
-> Provides MongoDB with graph or graph-like capabilities
Chapter 3: Core Aggregation - Combining Information
$graphLookup: Simple Lookup
Which of the following statements is/are correct? Check all that apply.
- connectToField will be used on recursive find operations
- connectFromField value will be use to match connectToField in a recursive match
Chapter 3: Core Aggregation - Combining Information
$graphLookup: Simple Lookup Reverse Schema
Chapter 3: Core Aggregation - Combining Information
$graphLookup: maxDepth and depthField
- maxDepth allows you to specify the number of recursive lookups
- depthField determines a field in the result document, which specifies the number of recursive lookups needed to reach that document
Chapter 3: Core Aggregation - Combining Information
$graphLookup: Cross Collection Lookup
Chapter 3: Core Aggregation - Combining Information
$graphLookup: General Considerations
Consider the following statement:
``$graphLookup`` is required to be the last element on the pipeline.
Which of the following is true about the statement?
- This is incorrect. $graphLookup can be used in any position of the pipeline and acts in the same way as a regular $lookup.
Chapter 3: Core Aggregation - Combining Information
Lab: $graphLookup
Now that you have been introduced to $graphLookup, let's use it to solve an interesting need. You are working for a travel agency and would like to find routes for a client! For this exercise, we'll be using the air_airlines, air_alliances, and air_routes collections in the aggregations database.
The air_airlines collection will use the following schema:
{
"_id" : ObjectId("56e9b497732b6122f8790280"),
"airline" : 4,
"name" : "2 Sqn No 1 Elementary Flying Training School",
"alias" : "",
"iata" : "WYT",
"icao" : "",
"active" : "N",
"country" : "United Kingdom",
"base" : "HGH"
}
The air_routes collection will use this schema:
{
"_id" : ObjectId("56e9b39b732b6122f877fa31"),
"airline" : {
"id" : 410,
"name" : "Aerocondor",
"alias" : "2B",
"iata" : "ARD"
},
"src_airport" : "CEK",
"dst_airport" : "KZN",
"codeshare" : "",
"stops" : 0,
"airplane" : "CR2"
}
Finally, the air_alliances collection will show the airlines that are in each alliance, with this schema:
{
"_id" : ObjectId("581288b9f374076da2e36fe5"),
"name" : "Star Alliance",
"airlines" : [
"Air Canada",
"Adria Airways",
"Avianca",
"Scandinavian Airlines",
"All Nippon Airways",
"Brussels Airlines",
"Shenzhen Airlines",
"Air China",
"Air New Zealand",
"Asiana Airlines",
"Copa Airlines",
"Croatia Airlines",
"EgyptAir",
"TAP Portugal",
"United Airlines",
"Turkish Airlines",
"Swiss International Air Lines",
"Lufthansa",
"EVA Air",
"South African Airways",
"Singapore Airlines"
]
}
Determine the approach that satisfies the following question in the most efficient manner:
Find the list of all possible distinct destinations, with at most one layover, departing from the base airports of airlines from Germany, Spain or Canada that are part of the "OneWorld" alliance. Include both the destination and which airline services that location. As a small hint, you should find 158 destinations.
Select the correct pipeline from the following set of options:
db.air_alliances.aggregate([{
$match: { name: "OneWorld" }
}, {
$graphLookup: {
startWith: "$airlines",
from: "air_airlines",
connectFromField: "name",
connectToField: "name",
as: "airlines",
maxDepth: 0,
restrictSearchWithMatch: {
country: { $in: ["Germany", "Spain", "Canada"] }
}
}
}, {
$graphLookup: {
startWith: "$airlines.base",
from: "air_routes",
connectFromField: "dst_airport",
connectToField: "src_airport",
as: "connections",
maxDepth: 1
}
}, {
$project: {
validAirlines: "$airlines.name",
"connections.dst_airport": 1,
"connections.airline.name": 1
}
},
{ $unwind: "$connections" },
{
$project: {
isValid: { $in: ["$connections.airline.name", "$validAirlines"] },
"connections.dst_airport": 1
}
},
{ $match: { isValid: true } },
{ $group: { _id: "$connections.dst_airport" } }
])
Chapter 4: Core Aggregation - Multidimensional Grouping
Facets: Introduction
Chapter 4: Core Aggregation - Multidimensional Grouping
Facets: Single Facet Query
https://www.mongodb.com/docs/manual/reference/operator/aggregation/sortByCount/?jmp=university
Which of the following aggregation pipelines are single facet queries?
[
{"$match": { "$text": {"$search": "network"}}},
{"$sortByCount": "$offices.city"}
]
[
{"$unwind": "$offices"},
{"$project": { "_id": "$name", "hq": "$offices.city"}},
{"$sortByCount": "$hq"},
{"$sort": {"_id":-1}},
{"$limit": 100}
]
Chapter 4: Core Aggregation - Multidimensional Grouping
Facets: Manual Buckets
https://www.mongodb.com/docs/manual/reference/operator/aggregation/bucket/?jmp=university
Assuming that field1 is composed of double values, ranging between 0 and Infinity, and field2 is of type string, which of the following stages are correct?
{'$bucket': { 'groupBy': '$field2', 'boundaries': [ "a", "asdas", "z" ], 'default': 'Others'}}
Chapter 4: Core Aggregation - Multidimensional Grouping
Facets: Auto Buckets
https://www.mongodb.com/docs/manual/reference/operator/aggregation/bucketAuto/
$bucketAuto (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$bucketAutoCategorizes incoming documents into a specific number of groups, called buckets, based on a specified expression. Bucket boundaries are automatically determined in an attempt to evenly distribute the documents into th
www.mongodb.com
Auto Bucketing will ...
- given a number of buckets, try to distribute documents evenly across buckets.
- adhere bucket boundaries to a numerical series set by the granularity option.
Chapter 4: Core Aggregation - Multidimensional Grouping
Facets: Multiple Facets
https://www.mongodb.com/docs/manual/reference/operator/aggregation/facet/?jmp=university
Which of the following statement(s) apply to the $facet stage?
- The $facet stage allows several sub-pipelines to be executed to produce multiple facets.
- The $facet stage allows the application to generate several different facets with one single database request.
Chapter 4: Core Aggregation - Multidimensional Grouping
Lab - $facets
How many movies are in both the top ten highest rated movies according to the imdb.rating and the metacritic fields? We should get these results with exactly one access to the database.
Hint: What is the intersection?

Chapter 4: Core Aggregation - Multidimensional Grouping
The $sortByCount Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/sortByCount/
$sortByCount (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$sortByCountGroups incoming documents based on the value of a specified expression, then computes the count of documents in each distinct group.Each output document contains two fields: an _id field containing the distinct group
www.mongodb.com
Chapter 5: Miscellaneous Aggregation
The $redact Stage
https://www.mongodb.com/docs/manual/reference/operator/aggregation/redact/
$redact (aggregation) — MongoDB Manual
Docs Home → MongoDB Manual$redactRestricts the contents of the documents based on information stored in the documents themselves.The $redact stage has the following prototype form:{ $redact: }The argument can be any valid expression as long as it resolve
www.mongodb.com
Chapter 5: Miscellaneous Aggregation
The $out Stage
Chapter 5: Miscellaneous Aggregation
$merge Overview
In MongoDB 4.2, the $merge Aggregation stage:
- can merge documents from an Aggregation and a target collection.
- can output to a collection in the same or different database.
- can output to a sharded collection.
Chapter 5: Miscellaneous Aggregation
$merge Syntax
Consider an Aggregation Pipeline using the new $merge stage that outputs to the employee_data collection.
If we are not expecting to find any matching documents in the employee_data collection, which of the following stages should we use?
{
$merge: {
into: "employee_data",
whenNotMatched: "insert",
whenMatched: "fail"
}
}
Chapter 5: Miscellaneous Aggregation
Using $merge for Single View
Chapter 5: Miscellaneous Aggregation
Using $merge for a Temporary Collection
Chapter 5: Miscellaneous Aggregation
Using $merge for Rollups
Chapter 5: Miscellaneous Aggregation
Homework: Using $merge
Consider a potential $merge stage that:
- outputs results to a collection called analytics.
- merges the results of the $merge stage with current analytics documents using the value of the name field.
- updates existing analytics documents to include any modified information from the resulting $merge documents.
- creates a new analytics document if an existing document with the resulting document's name does not exist.
Which of the following $merge stages will perform all of the above functionality?
{
$merge: {
into: "analytics",
on: "name",
whenMatched: "merge",
whenNotMatched: "insert"
}
}
Chapter 5: Miscellaneous Aggregation
Views
Which of the following statements are true regarding MongoDB Views?
- View performance can be increased by creating the appropriate indexes on the source collection.
Chapter 6: Aggregation Performance and Pipeline Optimization
Aggregation Performance
https://www.mongodb.com/docs/manual/core/query-plans/
Query Plans — MongoDB Manual
Docs Home → MongoDB ManualFor a query, the MongoDB query optimizer chooses and caches the most efficient query plan given the available indexes. The evaluation of the most efficient query plan is based on the number of "work units" (works) performed by t
www.mongodb.com
With regards to aggregation performance, which of the following are true?
- When $limit and $sort are close together a very performant top-k sort can be performed
- Transforming data in a pipeline stage prevents us from using indexes in the stages that follow
Chapter 6: Aggregation Performance and Pipeline Optimization
Aggregation Pipeline on a Sharded Cluster
https://www.mongodb.com/docs/manual/core/aggregation-pipeline-sharded-collections/?jmp=university
Aggregation Pipeline and Sharded Collections — MongoDB Manual
Docs Home → MongoDB ManualThe aggregation pipeline supports operations on sharded collections. This section describes behaviors specific to the aggregation pipeline and sharded collections.If the pipeline starts with an exact $match on a shard key, and t
www.mongodb.com
What operators will cause a merge stage on the primary shard for a database?
- $out
- $lookup
Chapter 6: Aggregation Performance and Pipeline Optimization
Pipeline Optimization - Part 1
Chapter 6: Aggregation Performance and Pipeline Optimization
Pipeline Optimization - Part 2
Which of the following statements is/are true?
- The query in a $match stage can be entirely covered by an index
- The Aggregation Framework will automatically reorder stages in certain conditions
- The Aggregation Framework can automatically project fields if the shape of the final document is only dependent upon those fields in the input document.
- Causing a merge in a sharded deployment will cause all subsequent pipeline stages to be performed in the same location as the merge
Final Exam
Final: Question 1
Consider the following aggregation pipelines:
Pipeline 1
db.coll.aggregate([
{"$match": {"field_a": {"$gt": 1983}}},
{"$project": { "field_a": "$field_a.1", "field_b": 1, "field_c": 1 }},
{"$replaceRoot":{"newRoot": {"_id": "$field_c", "field_b": "$field_b"}}},
{"$out": "coll2"},
{"$match": {"_id.field_f": {"$gt": 1}}},
{"$replaceRoot":{"newRoot": {"_id": "$field_b", "field_c": "$_id"}}}
])
Pipeline 2
db.coll.aggregate([
{"$match": {"field_a": {"$gt": 111}}},
{"$geoNear": {
"near": { "type": "Point", "coordinates": [ -73.99279 , 40.719296 ] },
"distanceField": "distance"}},
{"$project": { "distance": "$distance", "name": 1, "_id": 0 }}
])
Pipeline 3
db.coll.aggregate([
{
"$facet": {
"averageCount": [
{"$unwind": "$array_field"},
{"$group": {"_id": "$array_field", "count": {"$sum": 1}}}
],
"categorized": [{"$sortByCount": "$arrayField"}]
},
},
{
"$facet": {
"new_shape": [{"$project": {"range": "$categorized._id"}}],
"stats": [{"$match": {"range": 1}}, {"$indexStats": {}}]
}
}
])
Which of the following statements are correct?
Pipeline 2 is incorrect because $geoNear needs to be the first stage of our pipeline
Pipeline 3 fails because $indexStats must be the first stage in a pipeline and may not be used within a $facet
Pipeline 1 fails since $out is required to be the last stage of the pipeline
Final Exam
Final: Question 2
Consider the following collection:
db.collection.find()
{
"a": [1, 34, 13]
}
The following pipelines are executed on top of this collection, using a mixed set of different expression accross the different stages:
Pipeline 1
db.collection.aggregate([
{"$match": { "a" : {"$sum": 1} }},
{"$project": { "_id" : {"$addToSet": "$a"} }},
{"$group": { "_id" : "", "max_a": {"$max": "$_id"} }}
])
Pipeline 2
db.collection.aggregate([
{"$project": { "a_divided" : {"$divide": ["$a", 1]} }}
])
Pipeline 3
db.collection.aggregate([
{"$project": {"a": {"$max": "$a"}}},
{"$group": {"_id": "$$ROOT._id", "all_as": {"$sum": "$a"}}}
])
Given these pipelines, which of the following statements are correct?
- Pipeline 1 is incorrect because you cannot use an accumulator expression in a $match stage.
- Pipeline 3 is correct and will execute with no error
- Pipeline 2 fails because the $divide operator only supports numeric types
Final Exam
Final: Question 3
Consider the following collection documents:
db.people.find()
{ "_id" : 0, "name" : "Bernice Pope", "age" : 69, "date" : ISODate("2017-10-04T18:35:44.011Z") }
{ "_id" : 1, "name" : "Eric Malone", "age" : 57, "date" : ISODate("2017-10-04T18:35:44.014Z") }
{ "_id" : 2, "name" : "Blanche Miller", "age" : 35, "date" : ISODate("2017-10-04T18:35:44.015Z") }
{ "_id" : 3, "name" : "Sue Perez", "age" : 64, "date" : ISODate("2017-10-04T18:35:44.016Z") }
{ "_id" : 4, "name" : "Ryan White", "age" : 39, "date" : ISODate("2017-10-04T18:35:44.019Z") }
{ "_id" : 5, "name" : "Grace Payne", "age" : 56, "date" : ISODate("2017-10-04T18:35:44.020Z") }
{ "_id" : 6, "name" : "Jessie Yates", "age" : 53, "date" : ISODate("2017-10-04T18:35:44.020Z") }
{ "_id" : 7, "name" : "Herbert Mason", "age" : 37, "date" : ISODate("2017-10-04T18:35:44.020Z") }
{ "_id" : 8, "name" : "Jesse Jordan", "age" : 47, "date" : ISODate("2017-10-04T18:35:44.020Z") }
{ "_id" : 9, "name" : "Hulda Fuller", "age" : 25, "date" : ISODate("2017-10-04T18:35:44.020Z") }
And the aggregation pipeline execution result:
db.people.aggregate(pipeline)
{ "_id" : 8, "names" : [ "Sue Perez" ], "word" : "P" }
{ "_id" : 9, "names" : [ "Ryan White" ], "word" : "W" }
{ "_id" : 10, "names" : [ "Eric Malone", "Grace Payne" ], "word" : "MP" }
{ "_id" : 11, "names" : [ "Bernice Pope", "Jessie Yates", "Jesse Jordan", "Hulda Fuller" ], "word" : "PYJF" }
{ "_id" : 12, "names" : [ "Herbert Mason" ], "word" : "M" }
{ "_id" : 13, "names" : [ "Blanche Miller" ], "word" : "M" }
Which of the following pipelines generates the output result?
var pipeline = [{
"$project": {
"surname_capital": { "$substr": [{"$arrayElemAt": [ {"$split": [ "$name", " " ] }, 1]}, 0, 1 ] },
"name_size": { "$add" : [{"$strLenCP": "$name"}, -1]},
"name": 1
}
},
{
"$group": {
"_id": "$name_size",
"word": { "$push": "$surname_capital" },
"names": {"$push": "$name"}
}
},
{
"$project": {
"word": {
"$reduce": {
"input": "$word",
"initialValue": "",
"in": { "$concat": ["$$value", "$$this"] }
}
},
"names": 1
}
},
{
"$sort": { "_id": 1}
}
]
Final Exam
Final: Question 4
$facet is an aggregation stage that allows for sub-pipelines to be executed.
var pipeline = [
{
$match: { a: { $type: "int" } }
},
{
$project: {
_id: 0,
a_times_b: { $multiply: ["$a", "$b"] }
}
},
{
$facet: {
facet_1: [{ $sortByCount: "a_times_b" }],
facet_2: [{ $project: { abs_facet1: { $abs: "$facet_1._id" } } }],
facet_3: [
{
$facet: {
facet_3_1: [{ $bucketAuto: { groupBy: "$_id", buckets: 2 } }]
}
}
]
}
}
]
In the above pipeline, which uses $facet, there are some incorrect stages or/and expressions being used.
Which of the following statements point out errors in the pipeline?
- facet_2 uses the output of a parallel sub-pipeline, facet_1, to compute an expression
- can not nest a $facet stage as a sub-pipeline.
Final Exam
Final: Question 5
Consider a company producing solar panels and looking for the next markets they want to target in the USA. We have a collection with all the major cities (more than 100,000 inhabitants) from all over the World with recorded number of sunny days for some of the last years.
A sample document looks like the following:
db.cities.findOne()
{
"_id": 10,
"city": "San Diego",
"region": "CA",
"country": "USA",
"sunnydays": [220, 232, 205, 211, 242, 270]
}
The collection also has these indexes:
db.cities.getIndexes()
[
{
"v": 2,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "test.cities"
},
{
"v": 2,
"key": {
"city": 1
},
"name": "city_1",
"ns": "test.cities"
},
{
"v": 2,
"key": {
"country": 1
},
"name": "country_1",
"ns": "test.cities"
}
]
We would like to find the cities in the USA where the minimum number of sunny days is 200 and the average number of sunny days is at least 220. Lastly, we'd like to have the results sorted by the city's name. The matching documents may or may not have a different shape than the initial one.
We have the following query:
var pipeline = [
{"$addFields": { "min": {"$min": "$sunnydays"}}},
{"$addFields": { "mean": {"$avg": "$sunnydays" }}},
{"$sort": {"city": 1}},
{"$match": { "country": "USA", "min": {"$gte": 200}, "mean": {"$gte": 220}}}
]
db.cities.aggregate(pipeline)
However, this pipeline execution can be optimized!
Which of the following choices is still going to produce the expected results and likely improve the most the execution of this aggregation pipeline?
var pipeline = [
{"$match": { "country": "USA"}},
{"$addFields": { "mean": {"$avg": "$sunnydays"}}},
{"$match": { "mean": {"$gte": 220}, "sunnydays": {"$not": {"$lt": 200 }}}},
{"$sort": {"city": 1}}
]
Final Exam
Final: Question 6
Consider the following people collection:
db.people.find().limit(5)
{ "_id" : 0, "name" : "Iva Estrada", "age" : 95, "state" : "WA", "phone" : "(739) 557-2576", "ssn" : "901-34-4492" }
{ "_id" : 1, "name" : "Roger Walton", "age" : 92, "state" : "ID", "phone" : "(948) 527-2370", "ssn" : "498-61-9106" }
{ "_id" : 2, "name" : "Isaiah Norton", "age" : 26, "state" : "FL", "phone" : "(344) 479-5646", "ssn" : "052-49-6049" }
{ "_id" : 3, "name" : "Tillie Salazar", "age" : 88, "state" : "ND", "phone" : "(216) 414-5981", "ssn" : "708-26-3486" }
{ "_id" : 4, "name" : "Cecelia Wells", "age" : 16, "state" : "SD", "phone" : "(669) 809-9128", "ssn" : "977-00-7372" }
And the corresponding people_contacts view:
db.people_contacts.find().limit(5)
{ "_id" : 6585, "name" : "Aaron Alvarado", "phone" : "(631)*********", "ssn" : "********8014" }
{ "_id" : 8510, "name" : "Aaron Barnes", "phone" : "(944)*********", "ssn" : "********6820" }
{ "_id" : 6441, "name" : "Aaron Barton", "phone" : "(234)*********", "ssn" : "********1937" }
{ "_id" : 8180, "name" : "Aaron Coleman", "phone" : "(431)*********", "ssn" : "********7559" }
{ "_id" : 9738, "name" : "Aaron Fernandez", "phone" : "(578)*********", "ssn" : "********0211" }
Which of the of the following commands generates this people_contacts view?
var pipeline = [
{
"$sort": {"name": 1}
},
{
"$project": {"name":1,
"phone": {
"$concat": [
{"$arrayElemAt": [{"$split": ["$phone", " "]}, 0]} ,
"*********" ]
},
"ssn": {
"$concat": [
"********",
{"$arrayElemAt": [{"$split": ["$ssn", "-"]}, 2]}
]
}
}
}
];
db.createView("people_contacts", "people", pipeline);
Final Exam
Final: Question 7
Using the air_alliances and air_routes collections, find which alliance has the most unique carriers(airlines) operating between the airports JFK and LHR, in either directions.
Names are distinct, i.e. Delta != Delta Air Lines
src_airport and dst_airport contain the originating and terminating airport information.

-> OneWorld, with 5 carriers
'푸닥거리' 카테고리의 다른 글
| 아키텍처 패턴(Architecture Patterns), 디자인 패턴(Design Pattern) (0) | 2022.07.09 |
|---|---|
| M220P: MongoDB for Python Developers (0) | 2022.06.19 |
| InnoDBClusterSet (0) | 2022.06.16 |
| 외부화를 위한 Amazon의 선언 (0) | 2022.06.13 |
| ASP.NET Core Restfull API 및 postman 호출 with visual studio 2022 (0) | 2022.06.12 |




댓글