탐색적 자료 분석 Exploratory Data Analysis -> Insight
-> Numpy, Pandas: 데이터를 다루기 위한 패키지
-> Matplotlib, Seaborn: 데이터를 시각화 하기 위한 패키지
기계학습 Machine Learning -> Optimization
-> Scikit-learn: 기계학습 라이브러리
-> Statsmodels: 통계 라이브러리
Numpy 패키지
- 파이썬을 사용한 과학 컴퓨팅의 기본 패키지
- 넘파이의 주요 객체는 동종의 다차원 배열
- N 차원 배열 객체 생성 및 관리
- 선형 대수학, 푸리에 변환 기능, 난수 생성 기능
- 넘파이의 차원들은 축(axis)으로 불림
넘파이 주요 함수
- 배열 만들기: arange, array, copy, empty, empty_like, eye, fromfile, fromfunction, identity, linspace, logspace, mgrid, ogrid, ones, ones_like, r, zeros, zeros_like
- 모양 바꾸기: ndarray.astype, atleast_1d, atleast_2d, atleast_3d, mat
- 배열 조작하기: array_split, column_stack, concatenate, diagonal, dsplit, dstack, hsplit, hstack, ndarray.item, newaxis, ravel, repeat, reshape, resize, squeeze, sqapaxes, take, transpose, vsplit, vstack
- 찾기: all, any, nonzero, where
- 정렬하기: argmax, argmin, argsort, max, min, ptp, searchsorted, sort
- 배열 운영하기: choose, compress, cumprod, cumsum, inner, ndarray.fill, imag, prod, put, putmask, real, sum
- 기초 통계: cov, mean, std, var
- 선형 대수: cross, dot, outer, linalg.svd, vdot
import numpy as np
A = np.arange(15).reshape(3,5)
A
array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]])

ndarray 속성
- ndarray.ndim: 배열의 축(Axis) 수, 차원
A.ndim

- ndarray.shape: 각 차원의 배열 크기를 나타내는 정수 타입의 튜플, shape는 (n,m) 형태, 행렬은 n개의 행과 m개의 열, shape 튜플의 길이는 축의 수 ( ndim )
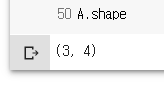
A.shape
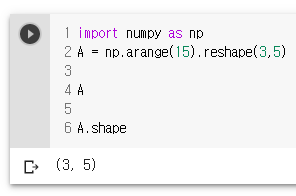
- darray.size: 배열의 요소의 총수, shape의 각 요소의 곱과 동일
A.size
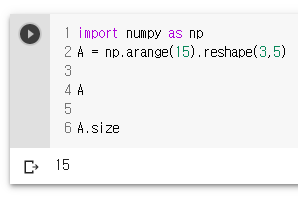
- ndarray.dtype: 배열 내의 요소의 타입, 파이썬의 자료형 또는 넘파이의 자료형(numpy.int32, numpy.int16, numpy.float64 등)을 이용해 지정함. 형변환의 개념이 아님, 지정한 타입의 크기만큼 잘라서 해당 타입으로 인식 함. 형변환은 astype(t) 함수를 이용
A.dtype -> dtype('int32')

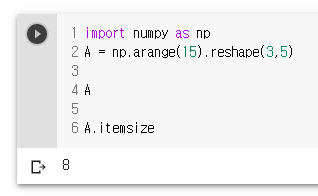
- ndarray.itemsize: 배열의 각 요소의 바이트 단위의 사이즈, float64 유형의 요소 배열에는 itemsize 8(=64/8), complex32 유형이는 itemsize 4(=32/8)가 있음. 이것은 ndarray.dtype.itemsize과 같은
A.itemsize

https://numpy.org/doc/stable/index.html

import numpy as np
A = np.array([2,3,4])
A
A.dtype

C = np.array([[1,2], [3,4]], dtype=complex)
C
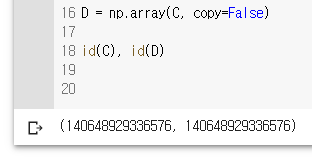
D = np.array(C, copy=False)
id(C), id(D)

E = np.array(A, copy=True)
id(E), id(A)

np.zeros((3,4))
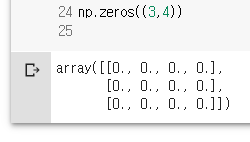
np.ones((2,3,4), dtype=np.int16)

np.empty((2,3)) # 메모리 상태에 따라 값이 달라짐

np.arange(10)
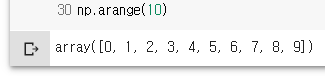
np.arange(11,20)
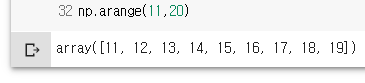
np.arange(10, 30, 5)
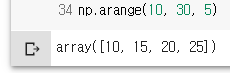
np.arange(0,2, 0.3)

np.linspace(0,2) # 끝 값 포함 됨

np.linspace(0,2,9)

np.linspace(0,10,20)

x = np.linspace(0, 2*np.pi, 100)
y = np.sin(x)
A = np.arange(12).reshape(3,4)
A

A.shape
A.ravel()


A.reshape(6,2)

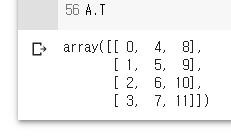
A.T
A.resize(2,6) # 현재 객체를 바꿈

A.shape

A.shape = (3,4)

A.reshape(2,-1) # 변경 된 배열이 반환 됨

A = np.arange(6)
print(A)


B = np.arange(12).reshape(4,3)
print(B)

C = np.arange(24).reshape(2,3,4)
C

print(np.arange(10000).reshape(100,100))

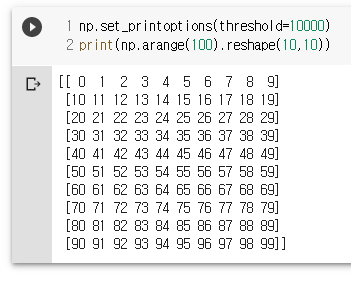
np.set_printoptions(threshold=10000)
print(np.arange(100).reshape(10,10))
A = np.array([20,30,40,50])
B = np.arange(4)
print(A)
print(B)
A - B

[1,2,3]*2

A*2

B ** 2

10 * np.sin(A)

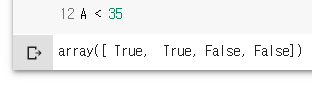
A < 35
A = np.array([[1,1],[0,1]])
B = np.array([[2,0],[3,4]])
A * B

A @ B # 행렬의 곱

A.dot(B) # 행렬의 곱

A = np.ones((2,3), dtype=int)
B = np.random.random((2,3))
A

B

A *= 3
A

B += 3
B

A += B
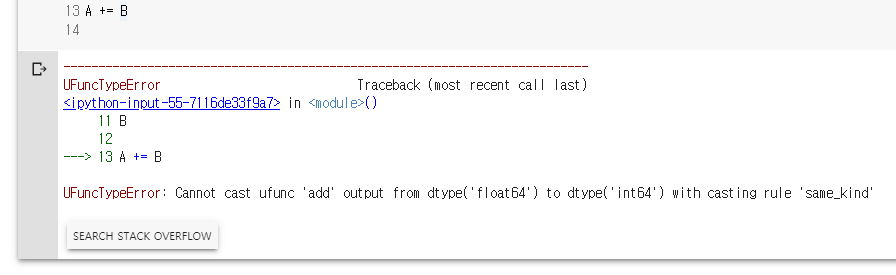
A = np.ones(3, dtype=np.int32)
B = np.linspace(0,np.pi,3)
B.dtype

C = A+B
C.dtype

A = np.random.random((2,3))
A
A.sum(), A.min(), A.max()

np.sum(A)

A = np.arange(12).reshape(3,4)
A
A.sum(axis=0) # 0은 행, 열은 고정하고 행 인덱스가 바뀌는 것들의 집계

np.sum(A, axis=0)

A.sum(axis=1) # 1은 행은 고정하고 열 인덱스가 바뀌는 것들의 집계

B = np.arange(24).reshape(2,3,4)
B

B[1,2,1] # 면(깊이), 행, 열

B.sum()

B.sum(axis=0) # 0은 면(깊이), 행과 열이 같은 것 집계

B.sum(axis=1) # 1은 행 인덱스가 바뀌는 것, 깊이와 열은 같은 것 집계


B.sum(axis=2) # 2는 깊이와 행은 고정, 열이 바뀐것들 집계

A = np.arange(12).reshape(3,4)
A

A.sum(axis=0) # 열을 고정시키고 행 인덱스가 바뀌는 것

reshape: 변경 된 배열이 반홤 됨, -1 값을 사용할 수 있음
resize: 현재 객체를 바꿈, -1값(음수)을 사용할 수 없음
2차원의 경우
axis = 0 일 경우 열인덱스는 고정이고, 행인덱스가 바뀌는 데이터를 집계
3차원의 경우
axis = 0 일 경우 행과 열인덱스를 고정하고 깊이(면)인덱스가 바뀌는 데이터 집계
axis = 1 일 경우 깊이와 열인덱스 고정, 행인덱스가 바뀌는 데이터 집계
A = np.arange(3)
B = np.arange(4,7)
print(A)
print(B)
A + B

np.add(A,B)
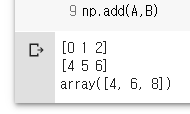
id(A), id(B) # 주소 값

np.add(A, B, A) # A 와 B를 더합 값을 A로

A = np.arange(3)
B = np.arange(4,7)
A + B
print(id(A)), print(id(B)) # 주소 값
np.add(A, B, A) # A 와 B를 더합 값을 A로
id(A)

A = np.arange(3)
B = np.arange(4,7)
C = np.array([20,30,40])
print(A)
print(B)
print(C)

A = np.arange(3)
B = np.arange(4,7)
C = np.array([20,30,40])
print(A)
print(B)
print(C)
G = A*B+C
T1 = A * B
G = T1 + C
del T1
G = A * B
np.add(G,C,G)
G = A * B
G += C

numpy 범용함수
https://numpy.org/doc/stable/reference/ufuncs.html
import numpy as np
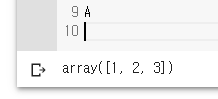
A = np.array([1,2,3])
B = np.array([2,2,2])
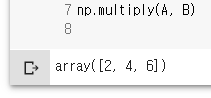
A * B

np.multiply(A, B)
B = 2
A * B

A = np.array([[0,0,0],
[10,10,10],
[20,20,20],
[30,30,30]])
B = np.array([1,2,3])
A + B

A = np.array([0,10,20,30])
B = np.array([1,2,3])
A[:, np.newaxis]
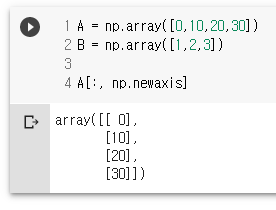

A = np.array([0,10,20,30])
B = np.array([1,2,3])
A[:, np.newaxis] # 축을 하나 추가 함
B
A[:,np.newaxis] + B # 4행 3열로 만들어짐

import numpy as np
A = np.arange(10)**3
A

A[2:5]

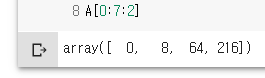
A[0:7:2]
A[::2]

A[::-1]

A[:6:2] = -1000
A

B = np.arange(20).reshape(5,4)
B

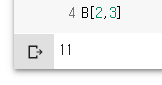
B[2,3]
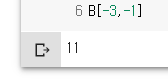
B[-3,-1]
C = np.arange(24).reshape(2,3,4)
C

C[0,1,2]
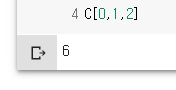
C[1,2,3]


B[0:5,1]

B[:,1]

B[1]
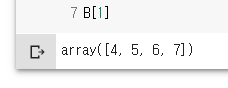

C[:,0:2,1:3]
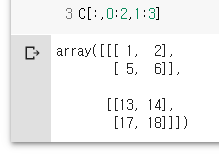
C[:,0:2,]

C[1]
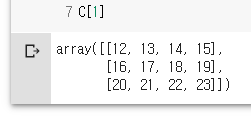
C[0:2]

배열 쌓기
hstack(), vstack(), dstack()
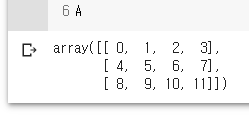
A = np.arange(12).reshape(3,4)
B = np.arange(12,24).reshape(3,4)
print(A)
print(B)

np.vstack((A,B)) # 배열을 아래에 추가하는 방식으로 쌓음

np.hstack((A,B)) # 배열을 옆에 추가하는 방식으로 쌓음

np.dstack((A,B)) # 3번째 축(depth)을 따라 쌓음

A = np.array((1,2,3,4))
B = np.array((5,6,7,8))
C = np.array((9,10,11,12))
print(A)
print(B)
print(C)

np.column_stack((A,B,C))

np.hstack((A,B))

A[:,np.newaxis]

np.hstack((A[:,np.newaxis], B[:,np.newaxis]))

np.row_stack((A,B))

np.vstack((A,B))

A = np.arange(12).reshape(3,4)
B = np.arange(12,24).reshape(3,4)
print(A)
print(B)

np.stack((A,B), axis=0)
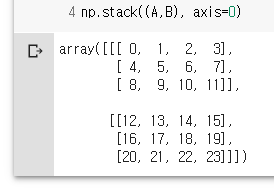
np.stack((A,B), axis=1) # axis 1은 행, 3차원

np.stack((A,B), axis=2) # axis 2은 열, 3차원

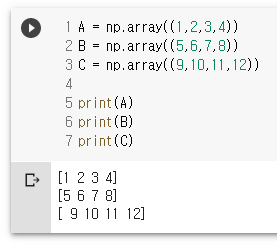
A = np.array((1,2,3,4))
B = np.array((5,6,7,8))
C = np.array((9,10,11,12))
print(A)
print(B)
print(C)
np.r_[A,B,C]

np.c_[A,B,C]

나누기
vsplit(), hsplit(), dsplit()
A = np.arange(12).reshape(3,4)
A

np.vsplit(A,3)

np.vsplit(A, 3)[0]

np.hsplit(A, 2)

np.hsplit(A, 4)

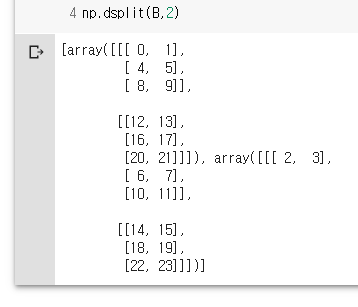
B = np.arange(24).reshape(2,3,4)
B

np.dsplit(B,2)
np.split(A,3, axis=0)

np.split(A, 2, axis=1)

np.hsplit(A,2)

# 2차원
- axis 0 은 행인덱스 변경, 열 고정
- axis 1은 열인덱스 변경, 행 고정
A = np.arange(24).reshape(3,8)
A

np.hsplit(A, 2)

np.hsplit(A, (2,5,6)) # 첫 인덱스부터 튜플로 지정한 각각의 인덱스까지 각각 부분 집합을 생성
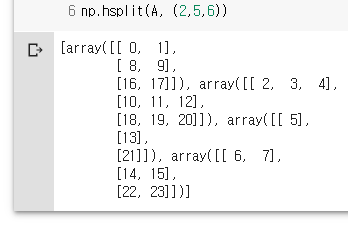
A = np.arange(12).reshape(3,4)
A

np.split(A, 2, axis=1)

np.array_split(A, 2, axis=0)

A = np.arange(10)
A

np.split(A, 4) # X 에러, 균등분할
-> np.array_split(A, 4) # 균등분할 아니어도 가능

슬라이싱,
stack: c_ , nreaxis 속성, 세로로 2차원 구조로 만들어 줌
split: 균등분할
appay_split 은 균등분할되지 않아도 됨
A = np.arange(12)
B = A
print(B)
print(A)

B.shape = (3,4)
B[::2,] = 0
print(B)
print(A)

A = np.arange(12).reshape(3,4)
C = A.view()
C is A
C.flags.owndata
C.shape = (2,6)
A[0,] = [10,20,30,40]

A = np.arange(12).reshape(3,4)
S = A[:,1:3]
S[:,1] = 100

A = np.arange(12).reshape(3,4)
D = A.copy()
D is A
D.shape = (2,6)
D[0,:] = [0,0,0,0,0,0]

import numpy as np
A = np.arange(12)**2
i = np.array([1,1,3,8,5])
A[i]
j = np.array([[3,4],[9,7]])
A[j]

A = np.arange(12).reshape(3,4)
ind_i = np.array([[0,1],[1,2]])
A[ind_i]
A[ind_i, :]
ind_j = np.array([[2,1],[3,3]])
A[ind_i, ind_j]

A = np.arange(5)
A[[1,3,4]] = 0

A = np.arange(5)
A[[0,0,2]] = [10,20,30]

A = np.arange(5)
A[[0,0,2]] += 1
A

A = np.array([2,3,4,5])
B = np.array([8,5,4])
np.ix_(A, B)

A = np.array([2,3,4,5])
B = np.array([8,5,4])
C = np.array([5,4,6,8,3])
np.ix_(A,B,C)
AX, BX = np.ix_(A,B)
AX + BX
#A + B * C
AX, BX, CX = np.ix_(A,B,C)
AX + BX * CX

A = np.array([2,3,4,5])
B = np.array([8,5,4])
def reduce_func(*arrs, func=np.add):
aix = np.ix_(*arrs)
result = aix[0]
for item in aix[1:]:
result = func(result, item)
return result
reduce_func(A,B)
reduce_func(A,B, func=np.divide)
A = np.arange(20).reshape(4,5)
A
A % 2 == 0
A[A%2==0]
A[A%2==0] = A[A%2==0]**2
A
A[A%2==0] = 0
A

import numpy as np
A = np.array([[1,2],[3,4]])
A
A.T
B = np.array([[0,-1], [1,0]])
B
A @ B # 행렬의 곱
A.dot(B) # 행렬의 곱
np.dot(A, B) # 행렬의 곱
np.linalg.inv(A) # 역 행렬
np.eye(2) # 단위행렬
np.diag(A) # 대각행렬
np.trace(A) # 대각합
np.linalg.det(A) # 행렬식을 구함
# solve 선형방정식을 구함
x=[2, 3]
y=[6.8, 7.3]
A = np.c_[x, np.ones(2)]
A
B = np.array(y)
B
np.linalg.solve(A, B)
# y = wx + b, y = ax + b

import matplotlib.pyplot as plt
%matplotlib inline
x=[2, 3]
y=[6.8, 7.3]
plt.scatter(x, y)
plt.plot(x, np.multiply(x, 0.5)+5.8)
plt.show()

# eig 고유값과 고유백터를 구함
np.linalg.eig(A)

#svd() 함수는 특이값 분해, 결과는 U.S.V.T
np.linalg.svd(A)

# transpose 같은 차원 내에서 배열의 모양을 변경할 때 사용
imgs = np.ones(shape=[4,3,28,28])
imgs.shape
# 배열의 차원은 그대로 유지하면서, 채널정보를 가장 마지막으로 변경
trans_imgs = imgs.transpose([0,2,3,1])
trans_imgs.shape

# 점들이 많은 경우, 모델 추정 문제를 행렬식 형태로 표현한 후 에 선형대수학을 적용, 선형 연립 방정식
X = [32,64,96,118,126,144,152,158]
Y = [17,24,62,49,52,105,130,125]
A = np.c_[X, np.ones(len(X))]
A
B = np.array(Y)
B
inv_A = np.linalg.inv(A.T @ A) @ A.T # A의 의사역행렬
w, b = inv_A @ B
w, b # 기울기, 편향

import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(X,Y)
plt.plot(X, np.multiply(X, w)+b)
plt.show()

import pandas as pd
d = [{'col1':1, 'col2':3}, {'col1':2, 'col2':4}]
pd.DataFrame(data=d)

d = [{'col1':1, 'col2':3}, {'col1':2, 'col2':4}, {'col1':2}]
pd.DataFrame(d)

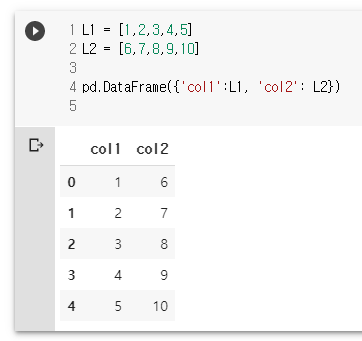
L1 = [1,2,3,4,5]
L2 = [6,7,8,9,10]
pd.DataFrame({'col1':L1, 'col2': L2})
import numpy as np
pd.DataFrame(np.c_[L1, L2], columns=['col1','col2'])

from sklearn import datasets
iris_dic = datasets.load_iris()
type(iris_dic)
print(iris_dic.target_names)

X = pd.DataFrame(iris_dic.data, columns=iris_dic.feature_names)
X

iris_dic.target_names[[0,0,1,1,2,2,2,2]]
y = pd.DataFrame(iris_dic.target_names[iris_dic.target], columns=['species'])
y

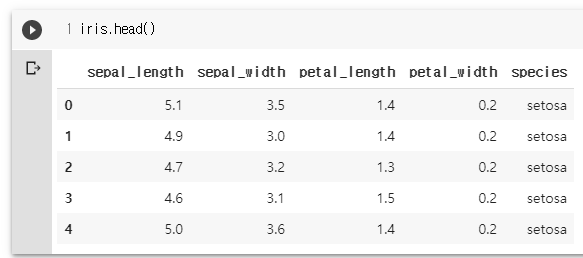
iris = pd.concat([X, y], axis=1)
iris.head()

import statsmodels.api as sm
iris_data = sm.datasets.get_rdataset("iris", package="datasets", cache=True)
type(iris_data)

iris_data.data

import seaborn as sns
iris = sns.load_dataset("iris")
type(iris)

iris.head()
iris['sepal_length']
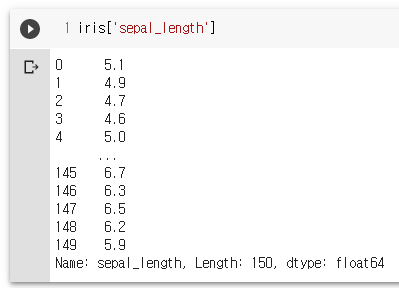
iris.to_csv("iris.csv.gz", sep=',', mode='w', encoding='utf-8', index=False, compression='infer')
del iris
iris = pd.read_csv("iris.csv")
iris.head()

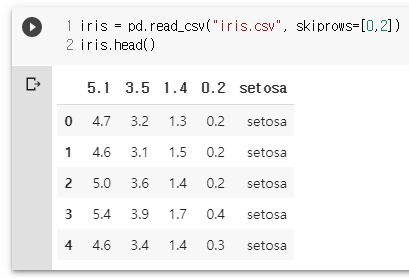
iris = pd.read_csv("iris.csv", skiprows=[0,2])
iris.head()
import seaborn as sns
iris = sns.load_dataset("iris")
iris.columns # 열의 이름

iris.columns = ["sl",'sw', "pl", "pw", "sp"]
iris.head()

iris.index

iris.index = range(150, 300)
iris.head()

iris.columns = \
[["sepal", "sepal", "petal", "petal", "species"],
["length", "width", "length", "width", "species"]]
iris.head()

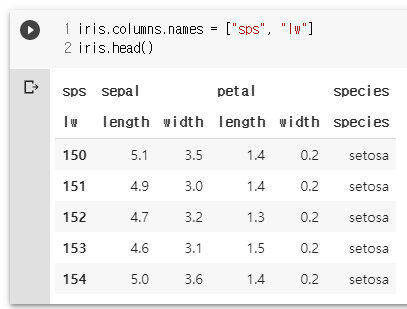
iris.columns.names = ["sps", "lw"]
iris.head()
iris.index = [["setosa" for i in range(50)] +
["versicolor" for i in range(50)] +
["virginica" for i in range(50)],
list(range(150))]
iris.head(10)

iris.index.names = ["sp", "rownum"]
iris.head()

import seaborn as sns
iris = sns.load_dataset("iris")
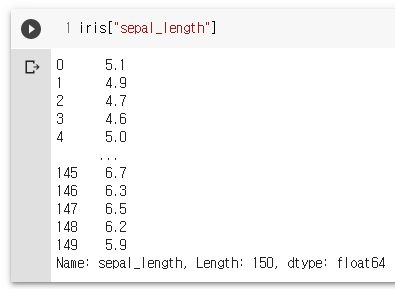
iris.sepal_length

iris["sepal_length"]
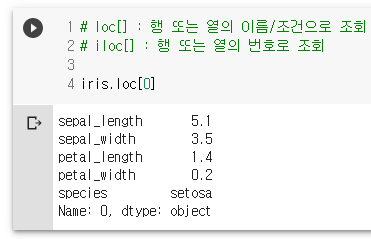
# loc[] : 행 또는 열의 이름/조건으로 조회
# iloc[] : 행 또는 열의 번호로 조회
iris.loc[0]
iris.loc[:, "sepal_length"]

iris.loc[0:5]

iris.loc[:, "sepal_width":"petal_width"]

iris.iloc[0:5]

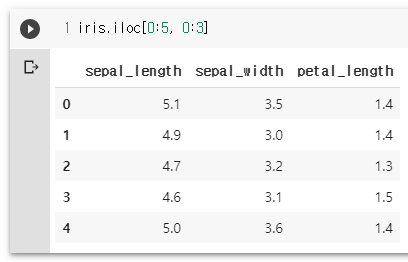
iris.iloc[0:5, 0:3]
iris.iloc[0:10:2, ::2]

iris.loc[iris.species=='versicolor']

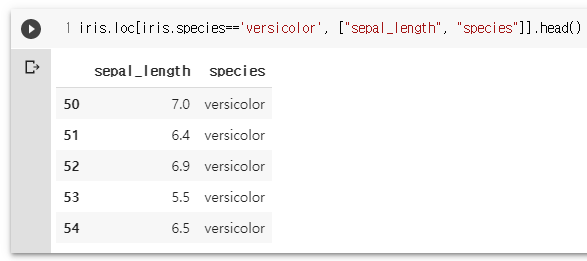
iris.loc[iris.species=='versicolor', ["sepal_length", "species"]].head()
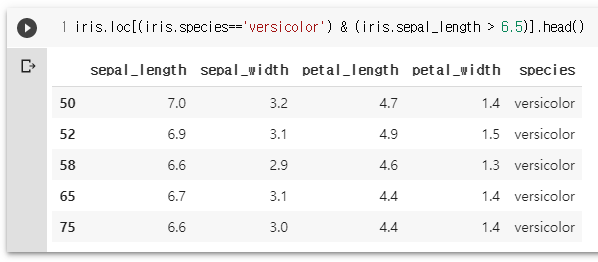
iris.loc[(iris.species=='versicolor') & (iris.sepal_length > 6.5)].head()
import seaborn as sns
iris = sns.load_dataset("iris")
iris.drop(0)

iris = sns.load_dataset("iris")
iris.drop(0, inplace=True) # 현재 객체를 바꿈
iris.head()
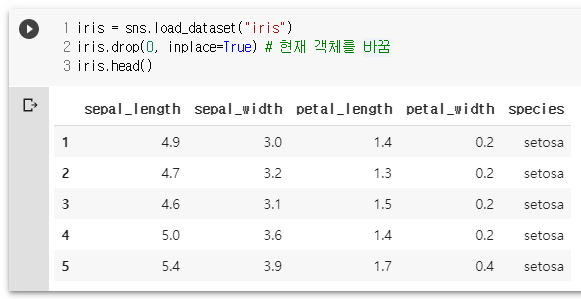
iris.drop("species", axis=1).head()

iris = sns.load_dataset("iris")
iris.species

iris["species"]

iris.year = 2020
iris.head()

iris.year
iris["year"] = 2020
iris.head()

iris["no2"] = [10,20,30] + [None]*147
iris.head()

iris["no3"] = None
iris.head()
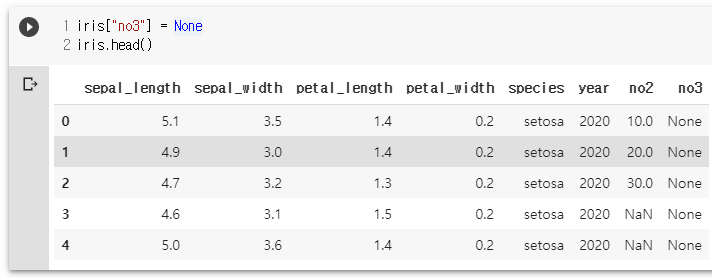
iris.loc[0:2, "no3"] = [10,20,30]
iris.head()

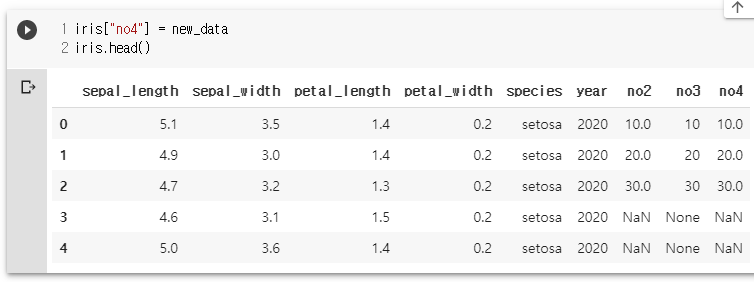
import pandas as pd
new_data = pd.Series([10,20,30], index=[0,1,2])
new_data

iris["no4"] = new_data
iris.head()
iris = sns.load_dataset("iris")
row1 = {"sepal_length":10, "sepal_width":5, "petal_length":20, "petal_width":10, "species":"setosa"}
row1

iris.append(row1, ignore_index=True).tail()
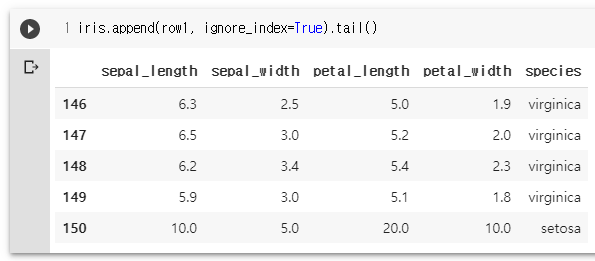
new_row = pd.Series([1,2,3,4,"versicolor"], index=iris.columns)
new_row

iris.append(new_row, ignore_index=True)

import pandas as pd
df1 = pd.DataFrame({'key': ['a','b','c','f'], 'c1':[1,2,3,5]})
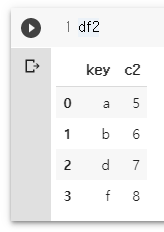
df2 = pd.DataFrame({'key': ['a','b','d','f'], 'c2':[5,6,7,8]})
df1.merge(df2)

df1.merge(df2, how='left')
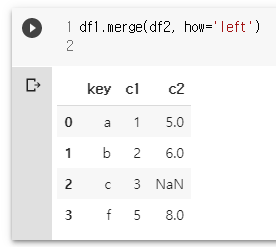
df1.merge(df2, how='right')

df1.merge(df2, how="outer") # 둘중에 한곳만 있어도

df1

df2
df3 = pd.DataFrame({'key3': ['a','b','c','f'], 'c1':[1,2,3,5]})
df4 = pd.DataFrame({'key4': ['a','b','d','f'], 'c2':[5,6,7,8]})
df3

df4
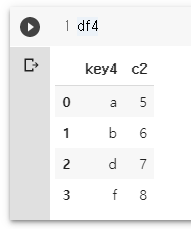
df3.merge(df4, left_on='key3', right_on='key4')

df3.merge(df4, left_index=True, right_index=True)

df1 = pd.DataFrame({'c1': [1,2,3,4], 'c2': [5,6,7,8]})
df2 = pd.DataFrame({'c3': ['a','b','c','d'], 'c4': [1.2, 3.4, 5.5, 7.6]})
pd.concat([df1, df2], axis=1) # axis 1 왼쪽에서 오른쪽으로,

pd.concat([df1, df2], axis=0)

df1 = pd.DataFrame({'c1': [1,2,3,4], 'c2': [5,6,7,8]}, index=[0,2,4,6])
df2 = pd.DataFrame({'c3': ['a','b','c','d'], 'c4': [1.2, 3.4, 5.5, 7.6]}, index=[0,1,2,3])
df1
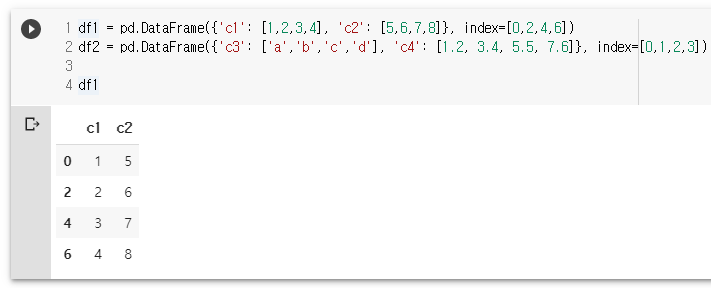
df2
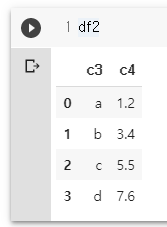
pd.concat([df1, df2], axis=1) # axis 1, 왼쪽에서 오른쪽으로
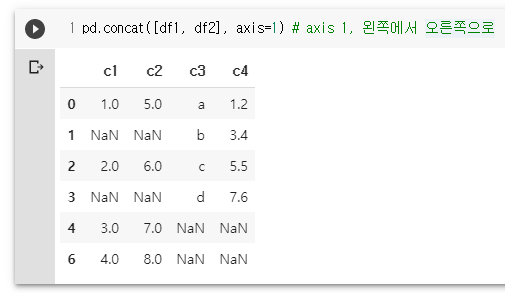
df1.reset_index()
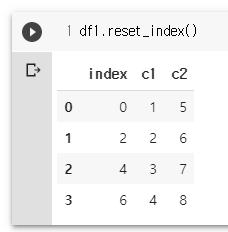
df1.reset_index(drop=True)

df1.reset_index(drop=True, inplace=True)
df1
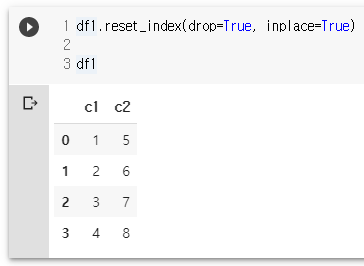
df2

pd.concat([df1, df2], axis=1)

import seaborn as sns
import pandas as pd
iris = sns.load_dataset("iris")
iris.head()

iris.sort_index(ascending=False).head()

iris.sort_index(axis=1).head()
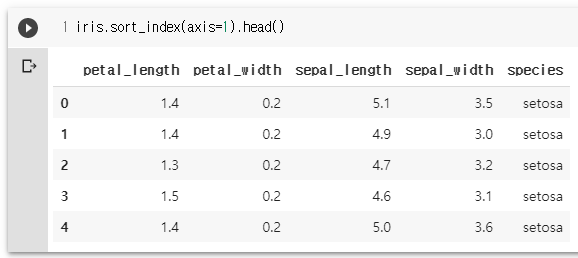
iris.sort_index(axis=1, inplace=True)
iris.head()

iris = sns.load_dataset("iris")
iris.sort_values(by=["sepal_length"], inplace=True)
iris.head()

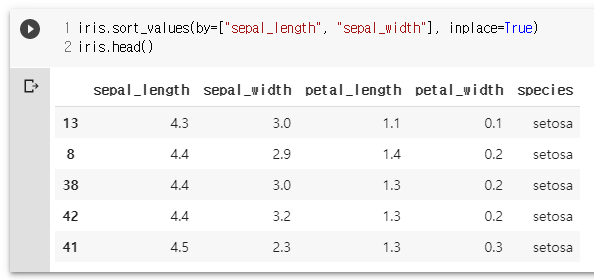
iris.sort_values(by=["sepal_length", "sepal_width"], inplace=True)
iris.head()
iris = sns.load_dataset("iris")
iris.columns = [["sepal","sepal","petal","petal","species"],iris.columns]
iris.columns.names = ["info", "details"]
iris.head()

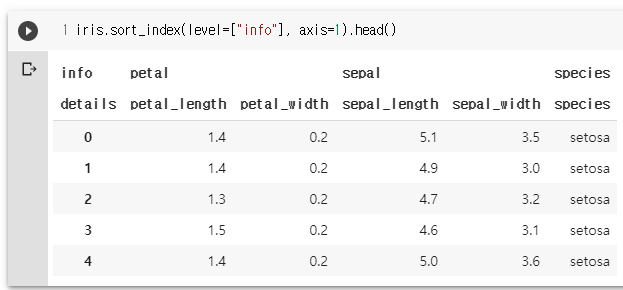
iris.sort_index(level=["info"], axis=1).head()
iris.sort_index(level=0, axis=1).head()

import seaborn as sns
iris = sns.load_dataset("iris")
iris.head()

iris.min() # 열 별로 최소 값

iris.max()

iris.median()

iris.mean() # 평균

iris.var() # 분산, 평균 값 데이터를 제곱하여 평균

iris.std() # 표준 편차

iris.std(ddof=1)

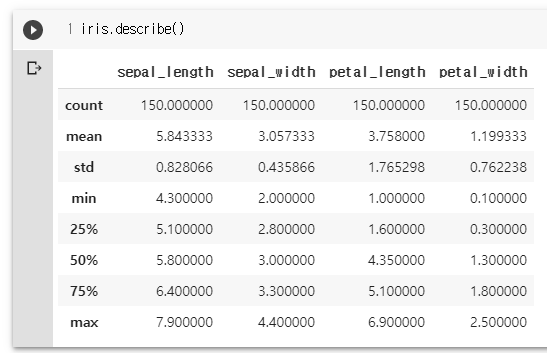
iris.cov() #공분산
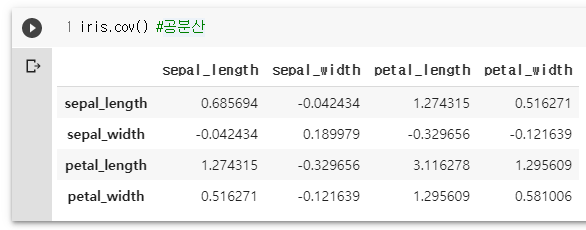
iris.corr() # 상관계수 0.3 작은 상관 관계 0.6 크면 강한 상관 관계
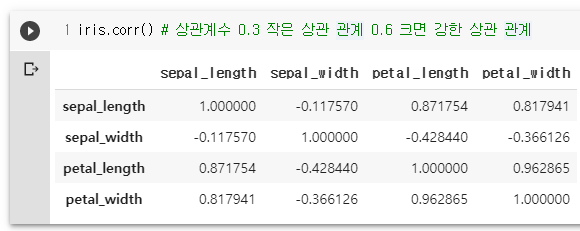
iris.describe()
iris.species.describe()

iris.describe(include="all")

import pandas as pd
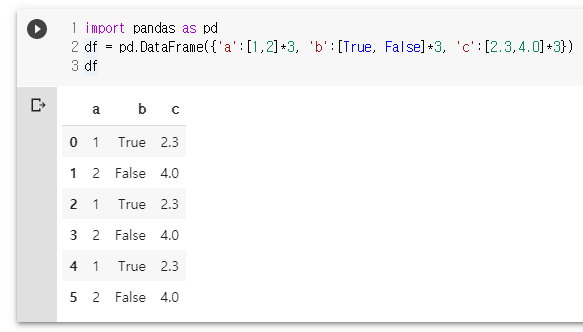
df = pd.DataFrame({'a':[1,2]*3, 'b':[True, False]*3, 'c':[2.3,4.0]*3})
df
df.describe(include=['int64'])
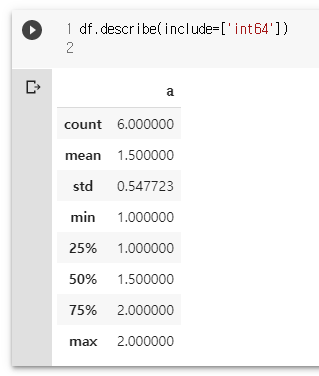
df.describe(exclude=["float64"])

import seaborn as sns
iris = sns.load_dataset("iris")
iris_grouped = iris.groupby(by=iris.species)
iris_grouped

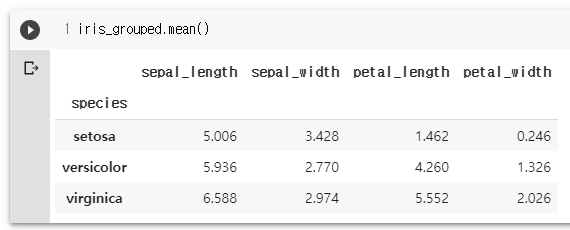
iris_grouped.mean()
import numpy as np
iris["num"] = np.ravel([[i]*25 for i in range(6)])
iris.head()

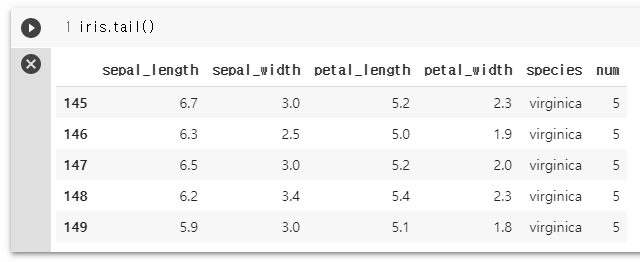
iris.tail()
iris_grouped2 = iris.groupby(by=[iris.species, iris.num])
iris_grouped2.mean()

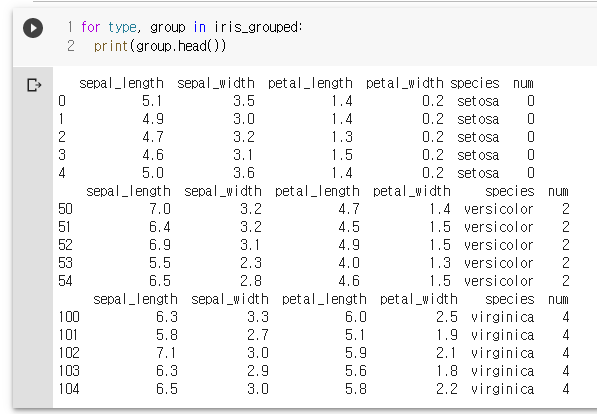
for type, group in iris_grouped:
print(group.head())
iris_grouped.take([1,2,3])

iris_grouped.take([0,1,2])
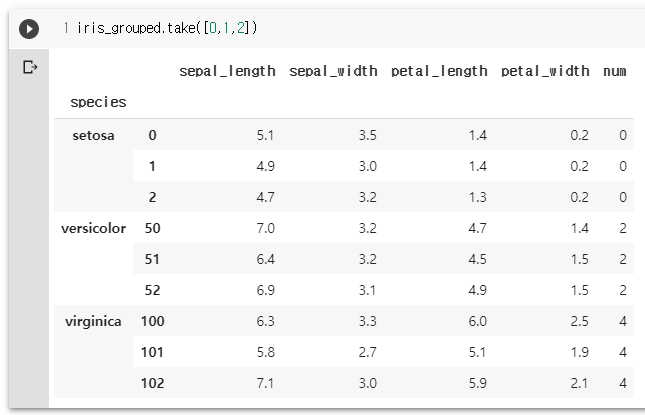
#데이터 구조 변경
import statsmodels.api as sm
airquality_data = sm.datasets.get_rdataset("airquality")
airquality = airquality_data.data
airquality.head()

import pandas as pd
pd.melt(airquality, id_vars=["Month", "Day"], value_vars=["Ozone"])
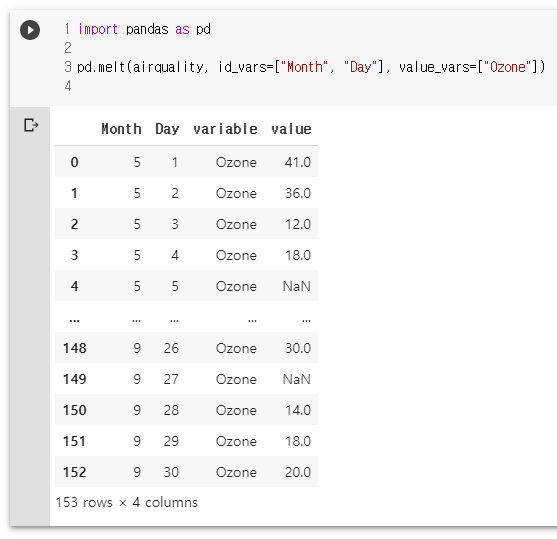
import pandas as pd
pd.melt(airquality, id_vars=["Month", "Day"], value_vars=["Ozone", "Solar.R"])

import pandas as pd
pd.melt(airquality, id_vars=["Month", "Day"], value_vars=["Ozone", "Solar.R", "Wind", "Temp"])

import pandas as pd
pd.melt(airquality, id_vars=["Month", "Day"])

airquality.melt(id_vars=["Month", "Day"])

# 롱포멧->와이드포멧
airquality_melted = airquality.melt(id_vars=["Month", "Day"])
airquality_melted.pivot_table(index=["Month", "Day"], columns=["variable"], values=["value"])

airquality2 = airquality_melted.pivot_table(index=["Month", "Day"], columns=["variable"], values=["value"])
airquality2.head()

airquality2.reset_index(level=["Month", "Day"], col_level=1)

airquality2 = airquality2.reset_index(level=["Month", "Day"], col_level=1)
airquality2.head()

airquality2.columns.droplevel(level=0)

airquality2.columns = airquality2.columns.droplevel(level=0)
airquality2.head()
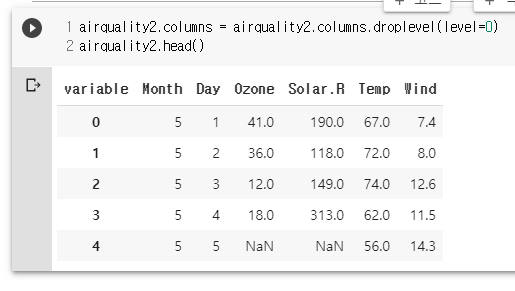
# 데이터프레임에 함수 적용
import seaborn as sns
iris_df = sns.load_dataset("iris")
import numpy as np
iris_df.iloc[:, :-1].apply(np.round).head()

iris_df.head()

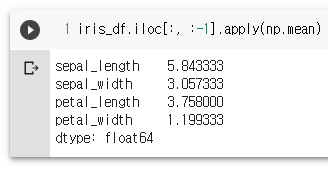
iris_df.iloc[:, :-1].apply(np.sum)

iris_df.iloc[:, :-1].apply(np.mean)
iris_df.iloc[:, :-1].apply(np.sum, axis=1)

iris_avg = iris_df.iloc[:, :-1].apply(np.average)
iris_avg
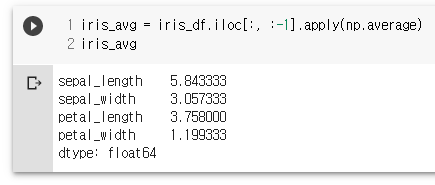
iris_df.iloc[:, :-1].apply(lambda x :x-iris_avg, axis=1).head()
# 모든 데이터들의 각 열의 평균과 차이

iris_df2 = iris_df.iloc[:, :-1]
iris_df2.apply(lambda x: list(x-iris_avg), axis=1).head()
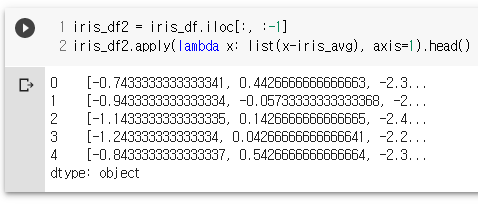
iris_df2.apply(lambda x: list(x-iris_avg), axis=1, result_type="broadcast").head()
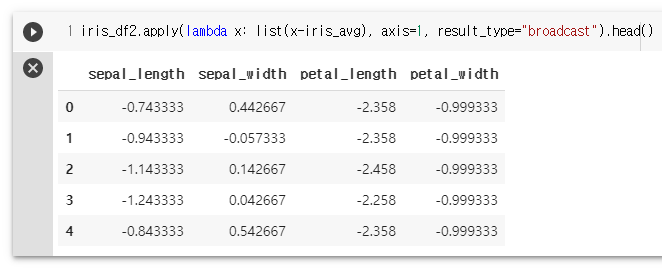
iris_df2.applymap(lambda x : x**2).head()
iris_df.sepal_length.map(np.round)

iris_df.sepal_length.map(np.sum)

# 결측지 처리 및 변경하기, 값 일괄 변경하기
import seaborn as sns
iris = sns.load_dataset("iris")
iris_x = iris.iloc[:,:-1]
import random
random.seed(1)
for col in range(4):
iris_x.iloc[[random.sample(range(len(iris)), 20)], col] = float('nan')
iris_x.head(15)

iris_x.dropna().head()

iris_x.dropna(thresh=2).head(10)

iris_x.dropna(subset=["sepal_length", "sepal_width"]).head()
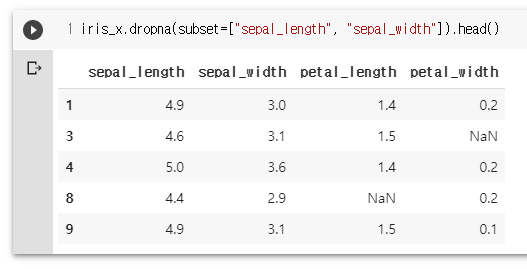
iris_x.dropna(inplace=True)
iris_x.head()

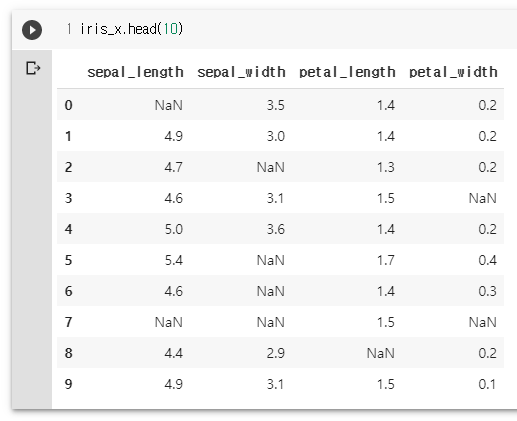
iris = sns.load_dataset("iris")
iris_x = iris.iloc[:,:-1]
import random
random.seed(1)
for col in range(4):
iris_x.iloc[[random.sample(range(len(iris)), 20)], col] = float('nan')
iris_x.fillna(value=0).head()

iris_x.fillna(method="ffill").head(10)
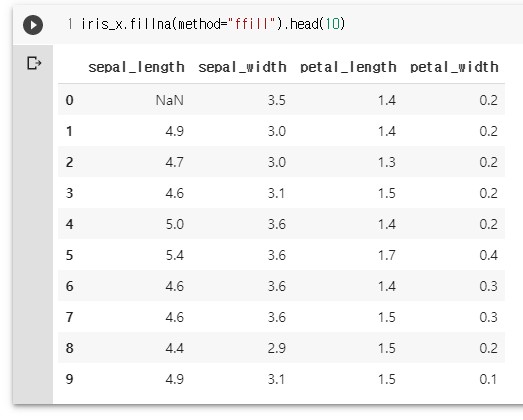
iris_x.head(10)
import numpy as np
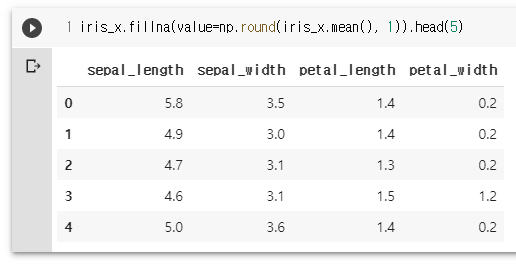
np.round(iris_x.mean(), 1)

iris_x.fillna(value=np.round(iris_x.mean(), 1)).head(5)
iris_x.fillna(value=np.round(iris_x.mean(), 1), limit=2).head(10)

iris_x.head(10)

iris = sns.load_dataset("iris")
iris_x = iris.iloc[:,:-1]
import random
random.seed(1)
for col in range(4):
iris_x.iloc[[random.sample(range(len(iris)), 20)], col] = float('nan')
iris_x.replace(float('nan'), 10).head()

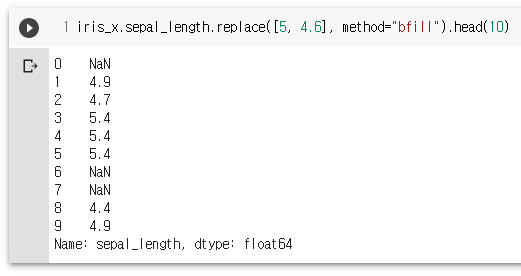
iris_x.sepal_length.replace([5, 4.6], method="bfill").head(10)
iris.replace(r"^se[a-z]*", "set", regex=True).head()

iris.head()

iris.replace(regex=r"^se[a-z]*", value="set").head()

import pandas as pd
df = pd.DataFrame({'A':[0,1,2,3,4], 'B':[5,6,7,8,9], 'C':['a','b','c','d','e']})
df

df.replace([0,1,2,3,4], 4)

df.replace([0,1,2,3], [4,3,2,1])

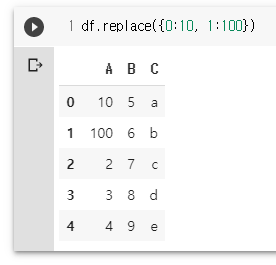
df.replace({0:10, 1:100})
df.replace({'A':0, 'B':5}, 100)

df.replace({'A': {0:100, 4:400}})

df = pd.DataFrame({'A':['bat', 'foo', 'bait'], 'B':['abc', 'bar', 'xyz']})
df

df.replace(r"^ba.$", 'new', regex=True)

df.replace({'A':r"^ba.$"}, {'A':'new'}, regex=True)

df.replace(regex=r"^ba.$", value="new")

df.replace(regex={r"^ba.$":'new', 'foo':'xyz'})

df.replace(regex=[r"^ba.$", "foo"], value="new")

s = pd.Series([10, 'a','a','b','a'])
s.replace({'a':None})

s.replace('a',None)

s.replace(to_replace='a', value=None, method='pad')

iris = sns.load_dataset("iris")
iris_x = iris.iloc[:,:-1]
iris_x.where(iris_x > 5).head(10)

iris_x.where(iris_x > 5, other=0).head(10)

df = pd.DataFrame(np.arange(10).reshape(-1,2), columns=["A","B"])
df

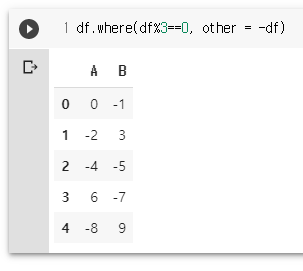
df.where(df%3==0, other = -df)
np.where(df%3==0, df, -df)

df.mask(~df%3==0, ~df)

iris_x.astype(int).head()

iris_x.astype({"sepal_length":int, "sepal_width":int}).head()

# Series: 1차원 자료구조
from pandas import Series, DataFrame
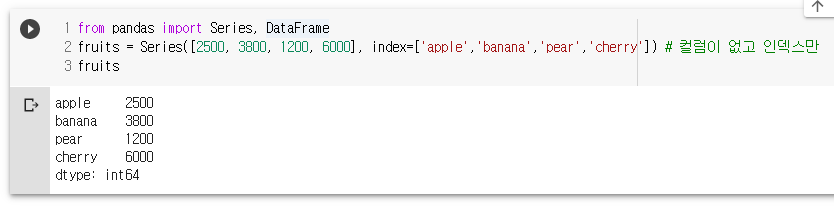
fruits = Series([2500, 3800, 1200, 6000], index=['apple','banana','pear','cherry']) # 컬럼이 없고 인덱스만
fruits
fruits.values

fruits.index

fruit_dic = {'apple':2500, 'banana':3800, 'pear':1200, 'cherry':6000}
type(fruit_dic)

fruits = Series(fruit_dic)
type(fruits)

fruits

fruits.values

fruits.index
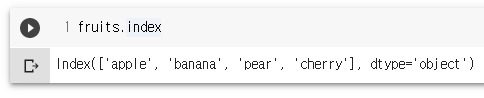
fruits.drop('banana')

fruits.drop('banana', inplace=True)
fruits
fruits[:]

fruits[0:2]

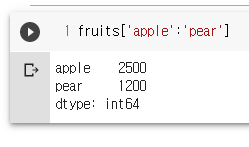
fruits['apple':'pear']
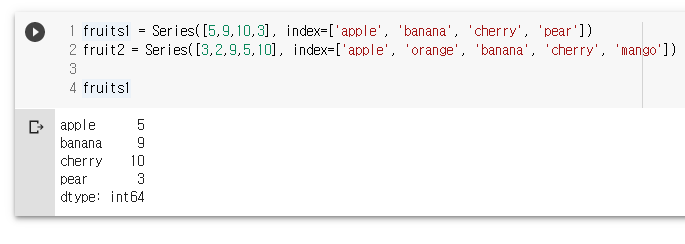
fruits1 = Series([5,9,10,3], index=['apple', 'banana', 'cherry', 'pear'])
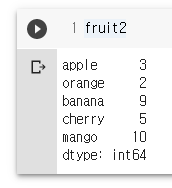
fruit2 = Series([3,2,9,5,10], index=['apple', 'orange', 'banana', 'cherry', 'mango'])
fruits1
fruit2
fruits1 + fruit2
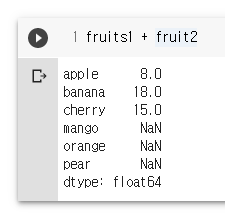
fruits = Series([2500, 3800, 1200, 6000], index=['apple', 'banana', 'pear','cherry'])
fruits.sort_values(ascending=False)

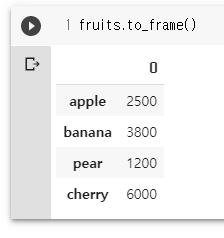
fruits.to_frame()
fruits.to_frame().T

# matplotlib.org, seaborn.pydata.org
https://matplotlib.org/tutorials/introductory/pyplot.html#sphx-glr-tutorials-introductory-pyplot-py
Pyplot tutorial — Matplotlib 3.3.0 documentation
text can be used to add text in an arbitrary location, and xlabel, ylabel and title are used to add text in the indicated locations (see Text in Matplotlib Plots for a more detailed example) All of the text functions return a matplotlib.text.Text instance.
matplotlib.org
https://plotnine.readthedocs.io/en/stable/
http://python-visualization.github.io/folium/
# Matplotlib
https://matplotlib.org/gallery
Thumbnail gallery — Matplotlib 2.0.2 documentation
matplotlib.org
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='retina'
import matplotlib
matplotlib.__version__
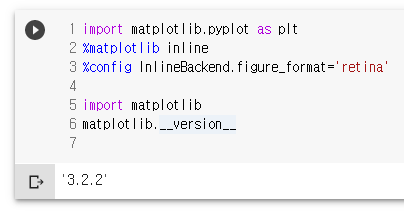
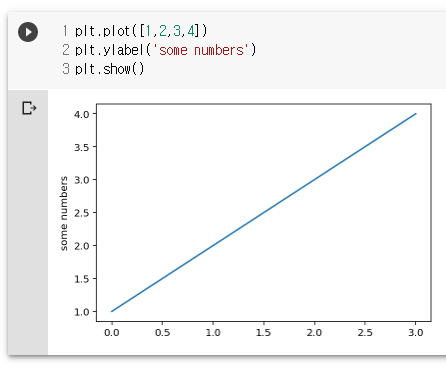
plt.plot([1,2,3,4])
plt.ylabel('some numbers')
plt.show()
plt.figure(figsize=(10,8)) #가로 10인치, 세로 8인치
plt.plot([1,2,3,4])
plt.ylabel('some numbers')
plt.show()

fig.set_size_inches(10,8)
plt.rcParam["figure.figsize"]=(10,8)
https://matplotlib.org/gallery/showcase/anatomy.html?highlight=anatomy
Anatomy of a figure — Matplotlib 3.3.0 documentation
Note Click here to download the full example code Anatomy of a figure This figure shows the name of several matplotlib elements composing a figure import numpy as np import matplotlib.pyplot as plt from matplotlib.ticker import AutoMinorLocator, MultipleLo
matplotlib.org
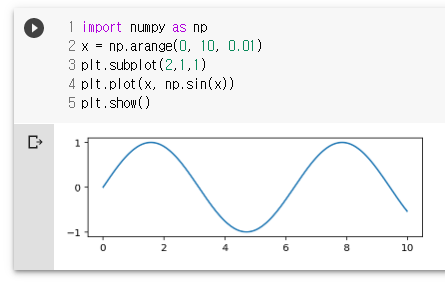
import numpy as np
x = np.arange(0, 10, 0.01)
plt.subplot(2,1,1)
plt.plot(x, np.sin(x))
plt.show()
import numpy as np
x = np.arange(0, 10, 0.01)
plt.subplot(2,1,1)
plt.plot(x, np.sin(x))
plt.subplot(223)
plt.plot(x, np.cos(x))
plt.subplot(224)
plt.plot(x, np.sin(x)*np.cos(x))
plt.show()

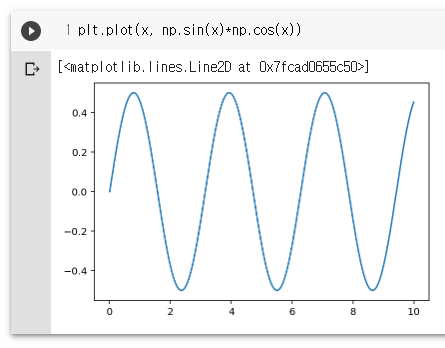
plt.plot(x, np.sin(x)*np.cos(x))
plt.show()

plt.plot(x, np.sin(x)*np.cos(x))
fig, axes = plt.subplots(nrows=2, ncols=2) # 도화지, 축 객체

fig # 도화지 객체
axes # 축 객체

axes[0,0].plot(x, np.sin(x))

fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].plot(x, np.sin(x))
plt.show()

fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].plot(x, np.sin(x))
axes[0,1].plot(x, np.cos(x))
axes[1,0].plot(x, np.tanh(x))
axes[1,1].plot(x, np.sin(x)*np.cos(x))
plt.show()

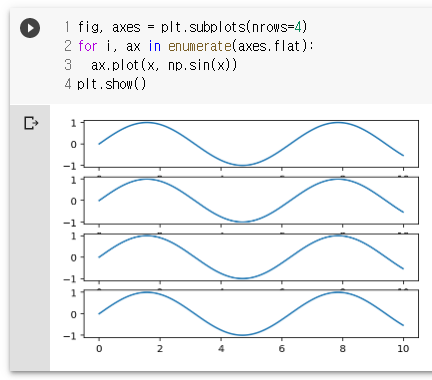
fig, axes = plt.subplots(nrows=4)
axes

fig, axes = plt.subplots(nrows=4)
for i, ax in enumerate(axes):
ax.plot(x, np.sin(x))
plt.show()

fig, axes = plt.subplots(nrows=4)
for i, ax in enumerate(axes.flat):
ax.plot(x, np.sin(x))
plt.show()
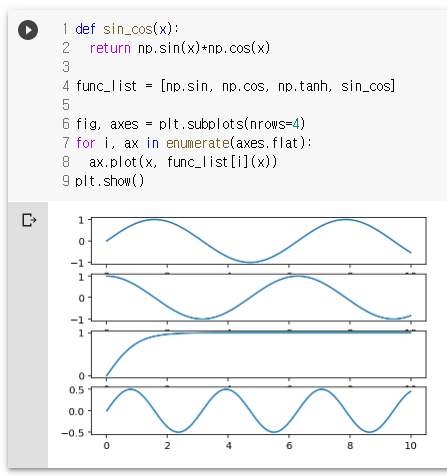
def sin_cos(x):
return np.sin(x)*np.cos(x)
func_list = [np.sin, np.cos, np.tanh, sin_cos]
fig, axes = plt.subplots(nrows=4)
for i, ax in enumerate(axes.flat):
ax.plot(x, func_list[i](x))
plt.show()
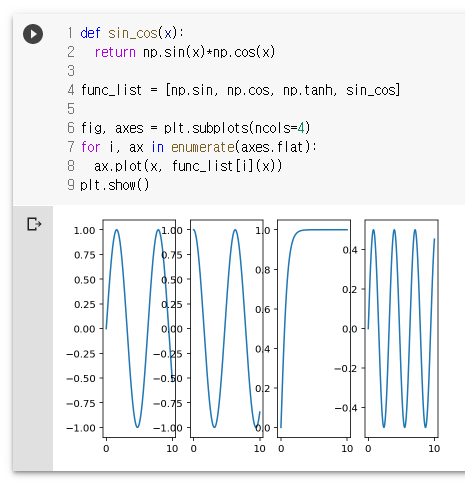
def sin_cos(x):
return np.sin(x)*np.cos(x)
func_list = [np.sin, np.cos, np.tanh, sin_cos]
fig, axes = plt.subplots(ncols=4)
for i, ax in enumerate(axes.flat):
ax.plot(x, func_list[i](x))
plt.show()
def sin_cos(x):
return np.sin(x)*np.cos(x)
func_list = [np.sin, np.cos, np.tanh, sin_cos]
fig, axes = plt.subplots(nrows=2, ncols=2)
for i, ax in enumerate(axes.flat):
ax.plot(x, func_list[i](x))
plt.show()

https://matplotlib.org/api/_as_gen/matplotlib.pyplot.html
matplotlib.pyplot — Matplotlib 3.3.0 documentation
matplotlib.pyplot matplotlib.pyplot is a state-based interface to matplotlib. It provides a MATLAB-like way of plotting. pyplot is mainly intended for interactive plots and simple cases of programmatic plot generation: import numpy as np import matplotlib.
matplotlib.org
fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
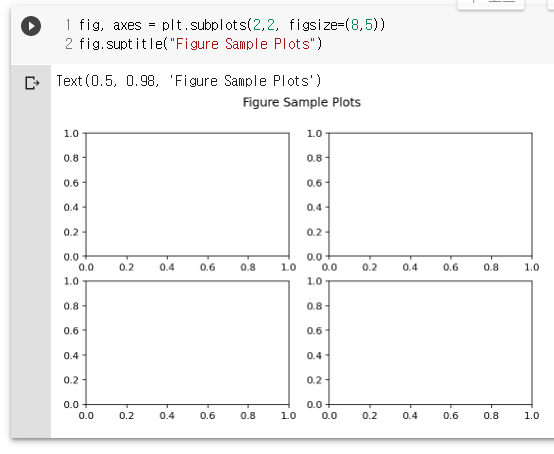
fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
axes[0,0].plot([1,2,3,4], 'ro-')
plt.show()

fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
axes[0,0].plot([1,2,3,4], 'ro--')
plt.show()

import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='retina'
fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
axes[0,0].plot([1,2,3,4], 'ro-')
axes[0,1].plot(np.random.randn(4,10), np.random.randn(4,10), 'cs-.')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='retina'
fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
axes[0,0].plot([1,2,3,4], 'ro-')
axes[0,1].plot(np.random.randn(4,10), np.random.randn(4,10), 'cs-.')
axes[1,0].plot(np.linspace(0,5), np.cos(np.linspace(0,5)))
plt.show()

import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='retina'
fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
axes[0,0].plot([1,2,3,4], 'ro-')
axes[0,1].plot(np.random.randn(4,10), np.random.randn(4,10), 'cs-.')
axes[1,0].plot(np.linspace(0,5), np.cos(np.linspace(0,5)))
axes[1,1].plot([3,6], [3,5], 'b^:')
plt.show()

import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='retina'
fig, axes = plt.subplots(2,2, figsize=(8,5))
fig.suptitle("Figure Sample Plots")
axes[0,0].plot([1,2,3,4], 'ro-')
axes[0,1].plot(np.random.randn(4,10), np.random.randn(4,10), 'cs-.')
axes[1,0].plot(np.linspace(0,5), np.cos(np.linspace(0,5)))
axes[1,1].plot([3,6], [3,5], 'b^:')
axes[1,1].plot([4,5], [5,4], 'kx--')
plt.show()
import seaborn as sns
iris = sns.load_dataset("iris")
plt.scatter(x=iris.petal_length, y=iris.petal_width,
s=iris.sepal_length*10, c=iris.sepal_width,
alpha=0.5)
plt.show()

np.random.seed(7902)
N = 50
x = np.random.rand(50)
y = np.random.rand(N)
colors = np.random.rand(N)
area = (30*np.random.rand(N))**2
plt.scatter(x, y, s=area, c=colors, alpha=0.5)
plt.show()
plt.bar([1,2,3], [3,4,5])
plt.show()

plt.barh([1,3,5], [1,2,3])
plt.show()
plt.axvline(0.6)
plt.show()
plt.axhline(0.4)
plt.show()
plt.hist(iris.sepal_length, bins=10, color='r')
plt.show()
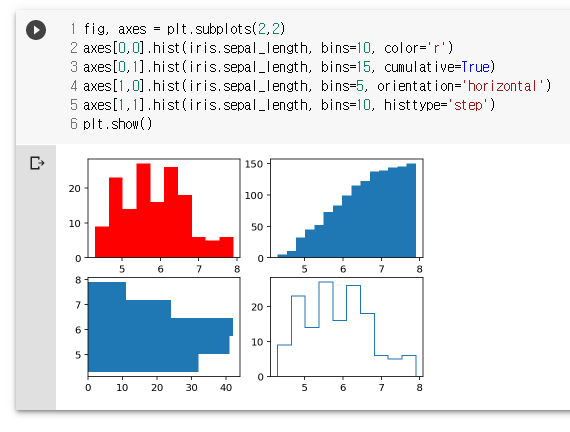
fig, axes = plt.subplots(2,2)
axes[0,0].hist(iris.sepal_length, bins=10, color='r')
axes[0,1].hist(iris.sepal_length, bins=15, cumulative=True)
axes[1,0].hist(iris.sepal_length, bins=5, orientation='horizontal')
axes[1,1].hist(iris.sepal_length, bins=10, histtype='step')
plt.show()
plt.boxplot(iris.sepal_length)
plt.show()

plt.violinplot(iris.sepal_length)
plt.show()

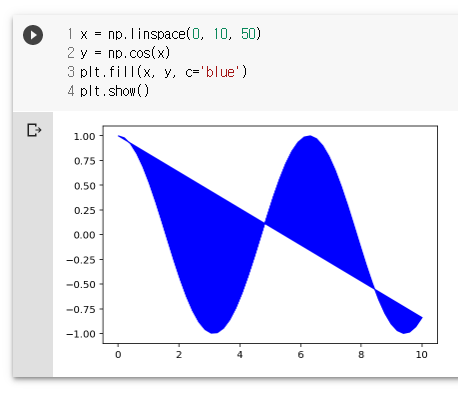
x = np.linspace(0, 10, 50)
y = np.cos(x)
plt.fill(x, y, c='blue')
plt.show()
plt.fill_between(x, y, color='red')
plt.show()

plt.fill_betweenx(x, y, color='red')
plt.show()

# Matplotlib을 이용한 시각화 2/2 – 그래프 커스터마이징
import numpy as np
import matplotlib.pyplot as plt
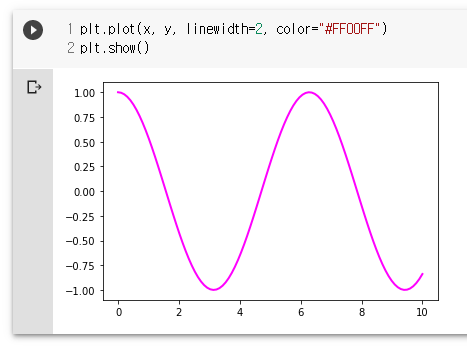
x = np.linspace(0, 10, 100)
y = np.cos(x)
plt.plot(x, y)
plt.show()

plt.plot(x, y, linewidth=2, color="#FF00FF")
plt.show()
plt.plot(x, y, linestyle="dotted", linewidth=7, color="purple")

plt.plot(x, y, ls="--", c="r", lw=3)
plt.show()

plt.plot(x, y, 'b^:')
plt.show()

plt.plot(x, y, 'b.')
plt.show()

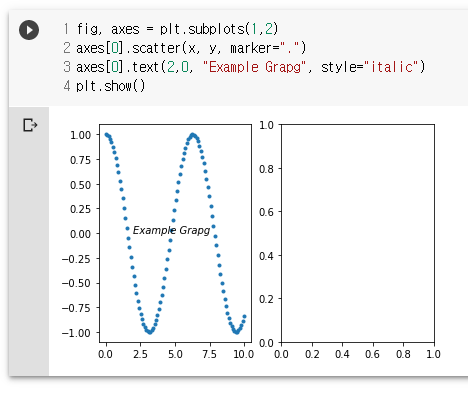
fig, axes = plt.subplots(1,2)
axes[0].scatter(x, y, marker=".")
axes[0].text(2,0, "Example Grapg", style="italic")
plt.show()
fig, axes = plt.subplots(1,2)
axes[0].scatter(x, y, marker=".")
axes[0].text(2,0, "Example Grapg", style="italic")
axes[1].scatter(x, y, marker="*")
axes[1].annotate("Sine", xy=(5,0.5), xytext=(2,0.75),
arrowprops=dict(arrowstyle="->", connectionstyle="angle3"))
plt.show()

# https://matplotlib.org/tutorials/text/annotations.html#sphx-glr-tutorials-text-annotations-py
Annotations — Matplotlib 3.3.0 documentation
Let's start with a simple example. text takes a bbox keyword argument, which draws a box around the text: t = ax.text( 0, 0, "Direction", ha="center", va="center", rotation=45, size=15, bbox=dict(boxstyle="rarrow,pad=0.3", fc="cyan", ec="b", lw=2)) The pat
matplotlib.org
plt.scatter(x, y, marker=".")
plt.text(3, 0.5, r"$\sum_{i=0}^\infty X_i$", fontsize=20)
plt.show()

# https://matplotlib.org/3.1.0/api/axis_api.html
matplotlib.axis — Matplotlib 3.1.0 documentation
matplotlib.axis Classes for the ticks and x and y axis. class matplotlib.axis.Axis(axes, pickradius=15)[source] Base class for XAxis and YAxis. class matplotlib.axis.XAxis(axes, pickradius=15)[source] class matplotlib.axis.YAxis(axes, pickradius=15)[source
matplotlib.org
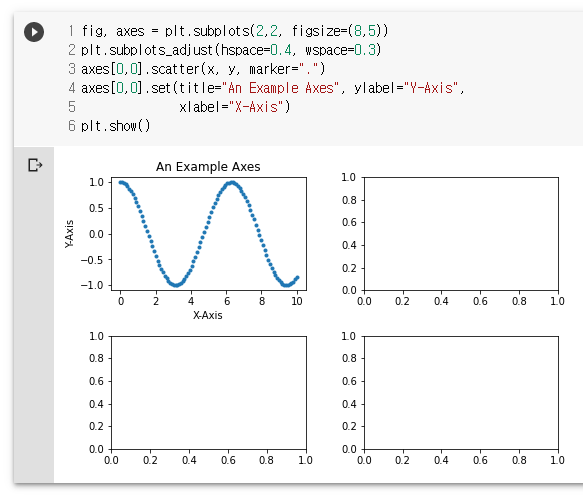
fig, axes = plt.subplots(2,2, figsize=(8,5))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
axes[0,0].scatter(x, y, marker=".")
axes[0,0].set(title="An Example Axes", ylabel="Y-Axis",
xlabel="X-Axis")
plt.show()
# 23:03 Matplotlib을 이용한 시각화 2/2 – 그래프 커스터마이징
import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,2, figsize=(8,5))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
axes[0,0].scatter(x, y, marker=".")
axes[0,0].set(title="An Example Axes", ylabel="Y-Axis",
xlabel="X-Axis")
axes[0,1].scatter(x, y, marker='^', c='r')
axes[0,1].set_xlim(0, 5)
axes[0,1].set_ylim(-2, 2)
axes[0,1].set_xlabel("X 0-5")
axes[0,1].set_ylabel("Y -2~2")
plt.show()

import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,2, figsize=(8,5))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
axes[0,0].scatter(x, y, marker=".")
axes[0,0].set(title="An Example Axes", ylabel="Y-Axis",
xlabel="X-Axis")
axes[0,1].scatter(x, y, marker='^', c='r')
axes[0,1].set_xlim(0, 5)
axes[0,1].set_ylim(-2, 2)
axes[0,1].set_xlabel("X 0-5")
axes[0,1].set_ylabel("Y -2~2")
axes[1,0].scatter(x, y, marker='v', c='b')
axes[1,0].set_xticks(range(1,8,2))
axes[1,0].set_xticklabels([3,100,-12,'foo'])
axes[1,0].set_yticks([-2,0,1,2])
axes[1,0].set_yticklabels([-200,0,100,"Max"])
plt.show()

import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,2, figsize=(8,5))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
axes[0,0].scatter(x, y, marker=".")
axes[0,0].set(title="An Example Axes", ylabel="Y-Axis",
xlabel="X-Axis")
axes[0,1].scatter(x, y, marker='^', c='r')
axes[0,1].set_xlim(0, 5)
axes[0,1].set_ylim(-2, 2)
axes[0,1].set_xlabel("X 0-5")
axes[0,1].set_ylabel("Y -2~2")
axes[1,0].scatter(x, y, marker='v', c='b')
axes[1,0].set_xticks(range(1,8,2))
axes[1,0].set_xticklabels([3,100,-12,'foo'])
axes[1,0].set_yticks([-2,0,1,2])
axes[1,0].set_yticklabels([-200,0,100,"Max"])
axes[1,1].scatter(x, y, marker=',', c='c')
axes[1,1].set(xticks=range(1,8,2), # axes[1,0].set_xticks(range(1,8,2)) 와 동일
xticklabels=[3,100,-12,'foo'],
yticks=[-2,0,1,2],
yticklabels=[-200,0,100,"Max"])
axes[1,1].spines["top"].set_visible(False)
axes[1,1].spines["bottom"].set_position(("outward", 10))
axes[1,1].grid(True)
plt.show()

axes[1,1].scatter(x, y, marker=',', c='c')
axes[1,1].set(xticks=range(1,8,2), # axes[1,0].set_xticks(range(1,8,2)) 와 동일
xticklabels=[3,100,-12,'foo'],
# yticks=[-2,0,1,2],
yticklabels=[-200,0,100,"Max"])
axes[1,1].spines["top"].set_visible(False)
axes[1,1].spines["bottom"].set_position(("outward", 10))
axes[1,1].grid(True)
plt.show()

x = np.arange(0,10)
y1 = 0.5 * x**2
y2 = -1*y1
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:") # 초록색, 삼각형, 점선
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
plt.show()

x = np.arange(0,10)
y1 = 0.5 * x**2
y2 = -1*y1
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:") # 초록색, 삼각형, 점선
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
ax2 = ax1.twinx() # 축 공유
ax2.plot(x, y2, 'bv--')
ax2.set_ylabel("Y2 data", color="b")
plt.show()

x = np.arange(0,10)
y1 = 0.5 * x**2
y2 = -1*y1
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:") # 초록색, 삼각형, 점선
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
ax2 = ax1.twinx() # 축 공유
ax2.plot(x, y2, 'bv--')
ax2.set_ylabel("Y2 data", color="b")
ax3 = ax1.twiny()
ax3.plot(-x, y1, 'ro-.')
ax3.set_xlabel('-x data', color="r")
plt.show()

fig, axes = plt.subplots(1,2, figsize=(8,3))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
plt.suptitle("Main Title")
plt.show()

fig, axes = plt.subplots(1,2, figsize=(8,3))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
plt.suptitle("Main Title")
axes[0].set_title("Title 1")
axes[0].set_xlabel("W")
plt.show()

fig, axes = plt.subplots(1,2, figsize=(8,3))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
plt.suptitle("Main Title")
axes[0].set_title("Title 1")
axes[0].set_xlabel("W")
axes[1].set(title="Title 2")
plt.show()

fig, axes = plt.subplots(1,2, figsize=(8,3))
plt.subplots_adjust(hspace=0.4, wspace=0.3)
plt.suptitle("Main Title")
axes[0].set_title("Title 1")
axes[0].set_xlabel("W")
axes[1].set_title("Title 2", loc="right")
axes[1].set_xlabel("X")
plt.show()

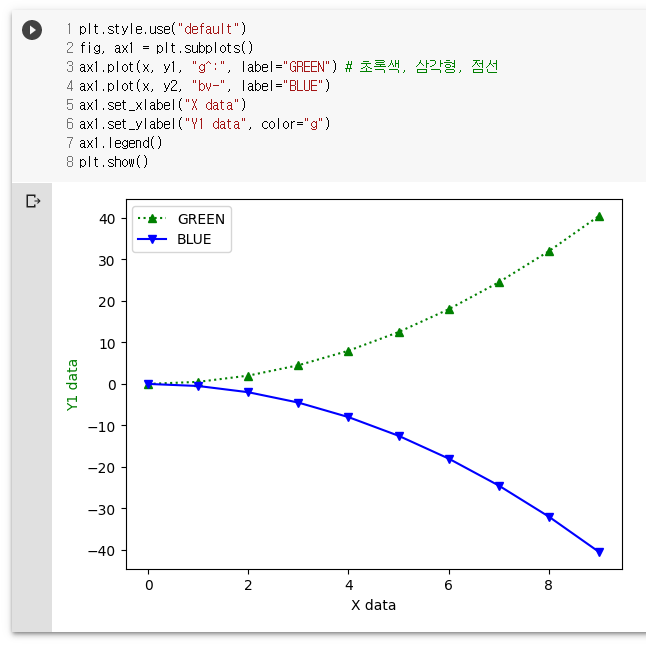
plt.style.use("default")
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:", label="GREEN") # 초록색, 삼각형, 점선
ax1.plot(x, y2, "bv-", label="BLUE")
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
ax1.legend()
plt.show()
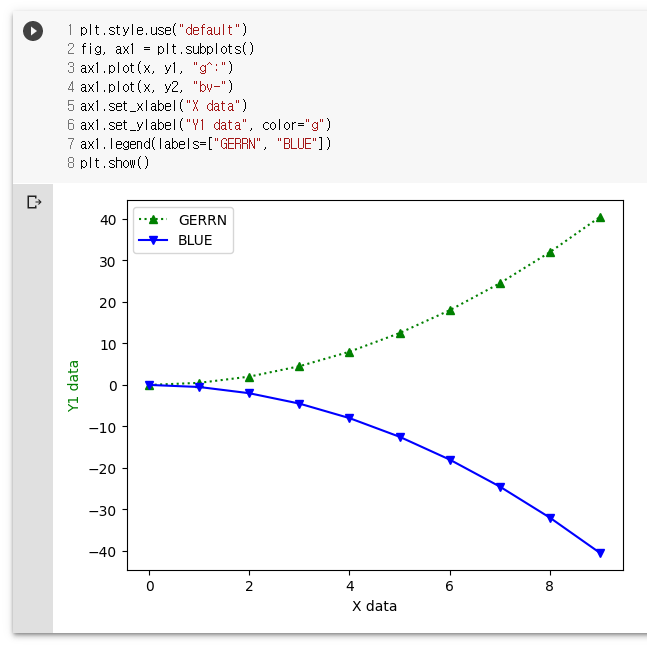
plt.style.use("default")
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:")
ax1.plot(x, y2, "bv-")
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
ax1.legend(labels=["GERRN", "BLUE"])
plt.show()
import numpy as np
x = np.arange(0, 10)
y = 0.5 * x**2
plt.style.use('default')
fig, ax1 = plt.subplots(figsize=(8,4))
ax1.plot(x, y, 'g^:')
ax1.set_xlabel('X data')
ax1.set_ylabel('Y data', color='g')
ax2 = ax1.twinx()
ax2.plot(x, -y, 'bv-.')
ax2.set_ylabel('-Y data', color='b')

import numpy as np
x = np.arange(0, 10)
y = 0.5 * x**2
plt.style.use('default')
fig, ax1 = plt.subplots(figsize=(8,4))
ax1.plot(x, y, 'g^:')
ax1.set_xlabel('X data')
ax1.set_ylabel('Y data', color='g')
ax2 = ax1.twinx()
ax2.plot(x, -y, 'bv-.')
ax2.set_ylabel('-Y data', color='b')
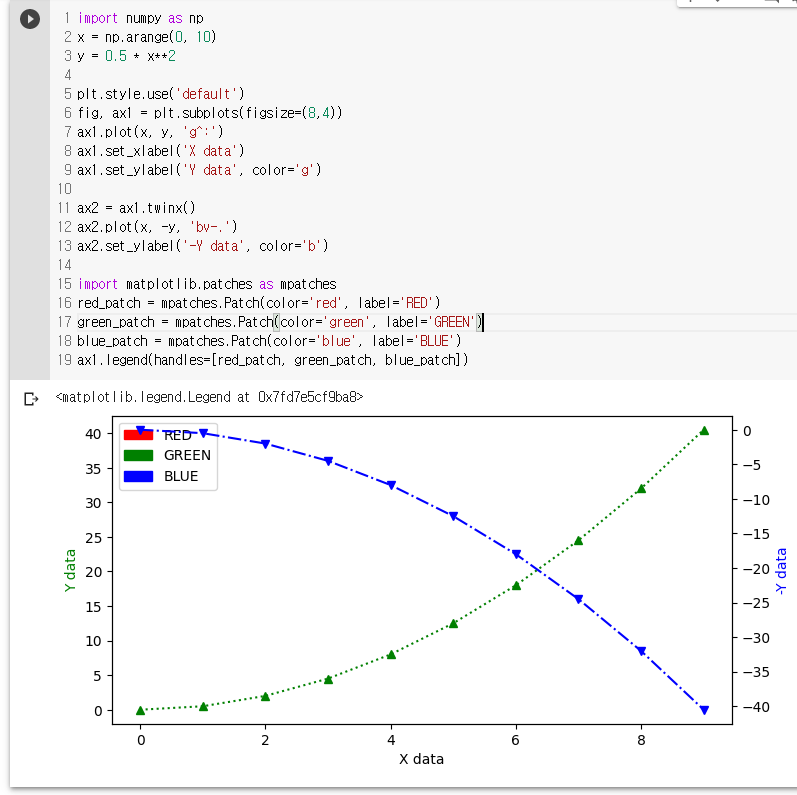
import matplotlib.patches as mpatches
red_patch = mpatches.Patch(color='red', label='RED')
green_patch = mpatches.Patch(color='green', label='GREEN')
blue_patch = mpatches.Patch(color='blue', label='BLUE')
ax1.legend(handles=[red_patch, green_patch, blue_patch])
import numpy as np
x = np.arange(0, 10)
y = 0.5 * x**2
plt.style.use('default')
fig, ax1 = plt.subplots(figsize=(8,4))
ax1.plot(x, y, 'g^:')
ax1.set_xlabel('X data')
ax1.set_ylabel('Y data', color='g')
ax2 = ax1.twinx()
ax2.plot(x, -y, 'bv-.')
ax2.set_ylabel('-Y data', color='b')
import matplotlib.patches as mpatches
red_patch = mpatches.Patch(color='red', label='RED')
green_patch = mpatches.Patch(color='green', label='GREEN')
blue_patch = mpatches.Patch(color='blue', label='BLUE')
ax1.legend(handles=[red_patch, green_patch, blue_patch])
import matplotlib.lines as mlines
dot_line = mlines.Line2D([], [], color='green',
marker='^', markersize=5,
linestyle=":", linewidth=2,
label='Dot Line')
dash_line = mlines.Line2D([], [], color='red',
marker='o', markersize=5,
linestyle="--", linewidth=2,
label='Dash Line')
dash_dot_line = mlines.Line2D([], [], color='blue',
marker='v', markersize=5,
linestyle="-.", linewidth=2,
label='Dash Dor Line')
ax2.legend(handles=[dot_line, dash_line, dash_dot_line],
loc='lower right', ncol=3, borderaxespad=3.,
mode="expand")

plt.style.use('ggplot')
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:")
ax1.plot(x, y2, "bv-")
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
ax1.legend(labels=["GERRN", "BLUE"])
plt.show()

plt.style.available

plt.style.use('default')
fig, ax1 = plt.subplots()
ax1.plot(x, y1, "g^:")
ax1.plot(x, y2, "bv-")
ax1.set_xlabel("X data")
ax1.set_ylabel("Y1 data", color="g")
ax1.legend(labels=["GERRN", "BLUE"])
plt.show()

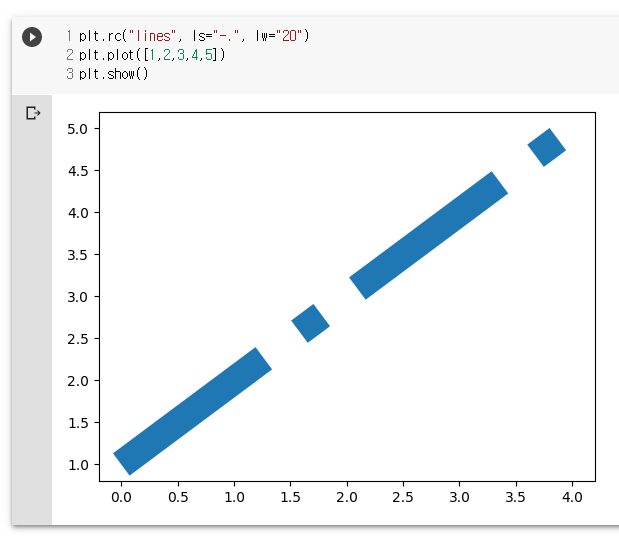
plt.rc("lines", ls="-.", lw="20")
plt.plot([1,2,3,4,5])
plt.show()
import matplotlib as mpl
plt.rc("lines", ls="-.", lw="20")
plt.rc("axes", prop_cycle=mpl.cycler(color=['g']))
plt.plot([1,2,3,4,5])
plt.show()

plt.rcParams["lines.linestyle"] = "-."
plt.rcParams["lines.linewidth"] = 20
plt.rcParams["axes.prop_cycle"] = mpl.cycler(color=["g"])
plt.plot([1,2,3,4,5])
plt.show()

# 주기표 cycler
from cycler import cycler
my_cycler = (cycler('color',
['r','g','b','c','m','y','k'])+
cycler(linestyle=['-','--',':','-.','-','--',':'])+
cycler(lw=np.linspace(5,20,7)))
plt.rcParams["axes.prop_cycle"] = my_cycler
plt.plot([1,2], [1,1])
plt.plot([1,2], [2,2])
plt.plot([1,2], [3,3])
plt.plot([1,2], [4,4])
plt.plot([1,2], [5,5])
plt.plot([1,2], [6,6])
plt.plot([1,2], [7,7])
plt.plot([1,2], [8,8])
plt.show()

# 그래프 저장
from cycler import cycler
my_cycler = (cycler('color',
['r','g','b','c','m','y','k'])+
cycler(linestyle=['-','--',':','-.','-','--',':'])+
cycler(lw=np.linspace(5,20,7)))
plt.rcParams["axes.prop_cycle"] = my_cycler
plt.plot([1,2], [1,1])
plt.plot([1,2], [2,2])
plt.plot([1,2], [3,3])
plt.plot([1,2], [4,4])
plt.plot([1,2], [5,5])
plt.plot([1,2], [6,6])
plt.plot([1,2], [7,7])
plt.plot([1,2], [8,8])
plt.savefig("poo.png", transparent=True)

# Seaborn을 이용한 시각화 1/2
seaborn: statistical data visualization — seaborn 0.10.1 documentation
Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. For a brief introduction to the ideas behind the library, you can read the introductory note
seaborn.pydata.org
http://seaborn.pydata.org/api.html
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
iris = sns.load_dataset("iris")
iris.head()

titanic = sns.load_dataset("titanic")
titanic.head()

iris.describe()
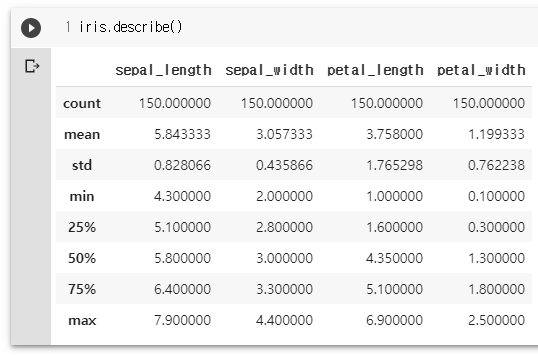
titanic.describe()

titanic.describe(include='all')

plt.style.use('ggplot')
fig, ax = plt.subplots(figsize=(5,6))
plt.show()
plt.style.available

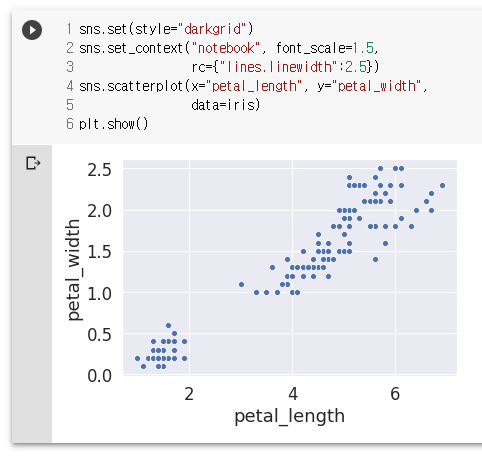
sns.set(style="darkgrid")
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth":2.5})
sns.scatterplot(x="petal_length", y="petal_width",
data=iris)
plt.show()
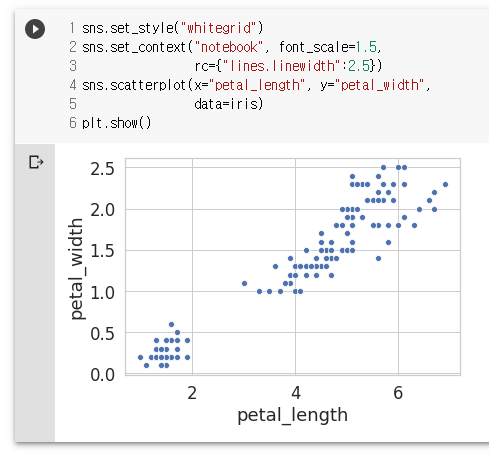
sns.set_style("whitegrid")
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth":2.5})
sns.scatterplot(x="petal_length", y="petal_width",
data=iris)
plt.show()
# 9:38 Seaborn을 이용한 시각화 1/2
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
iris = sns.load_dataset("iris")
sns.set(style="white")
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth":3.5})
sns.scatterplot(x="petal_length", y="petal_width",
data=iris)
sns.lineplot(x="petal_length", y="petal_width", data=iris)
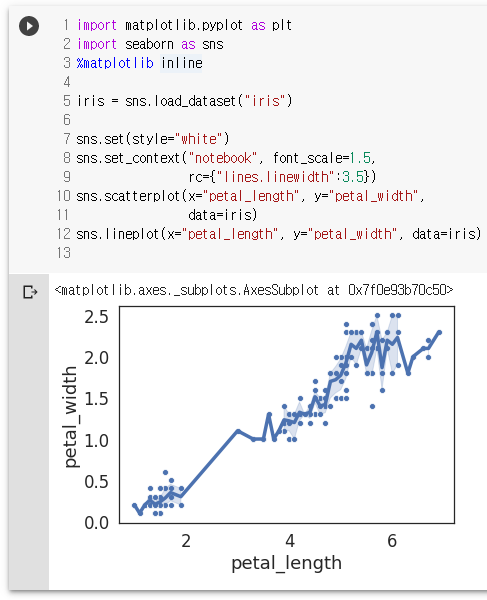
sns.set_palette("dark", 3)
sns.scatterplot(x="petal_length", y="petal_width",
data=iris, hue="species")
plt.show()

sns.set()
sns.scatterplot(x="petal_length", y="petal_width",
data=iris)

sns.set()
_ = sns.scatterplot(x="petal_length", y="petal_width",
data=iris)

sns.set()
sns.scatterplot(x="petal_length", y="petal_width",
data=iris)
plt.show()

sns.scatterplot(x="petal_length", y="petal_width",
hue="species", style="species",
data=iris)
plt.show()

sns.lineplot(x="petal_length", y="petal_width",
data=iris)
plt.show()

sns.lineplot(x="petal_length", y="petal_width",
hue="species", style="species",
data=iris)
plt.show()

sns.lineplot(x="petal_length", y="petal_width",
hue="species", style="species",
markers=True, dashes=False,
data=iris)
plt.show()

fig, axes = plt.subplots(ncols=2, figsize=(8,5))
plt.subplots_adjust(wspace=0.3)
sns.scatterplot(x="petal_length", y="petal_width",
data=iris, ax=axes[0])
sns.lineplot(x="petal_length", y="petal_width",
data=iris, ax=axes[1])
plt.show()

sns.scatterplot(x="petal_length", y="petal_width",
data=iris)
sns.lineplot(x="petal_length", y="petal_width",
data=iris)
plt.show()

sns.relplot(x="petal_length", y="petal_width",
col="species", data=iris)
plt.show()

sns.stripplot(x="species", y="petal_length", data=iris)
plt.show()

titanic = sns.load_dataset("titanic")
sns.barplot(x="sex", y="survived", hue="class",
data=titanic)
plt.show()

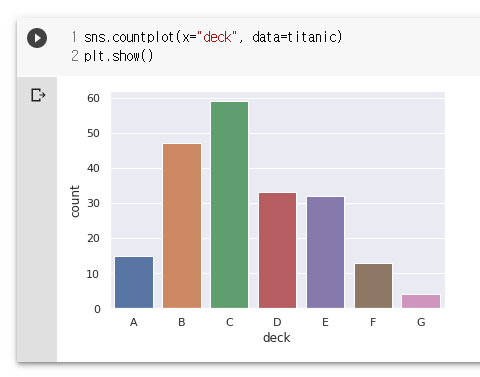
sns.countplot(x="deck", data=titanic)
plt.show()
sns.pointplot(x="class", y="survived", hue="sex",
data=titanic,
palette={"male":"g", "female":"m"},
markers=["^","o"], linestyles=["-","--"])
plt.show()

sns.boxplot(x="alive", y="age", hue="adult_male",
data=titanic)
plt.show()

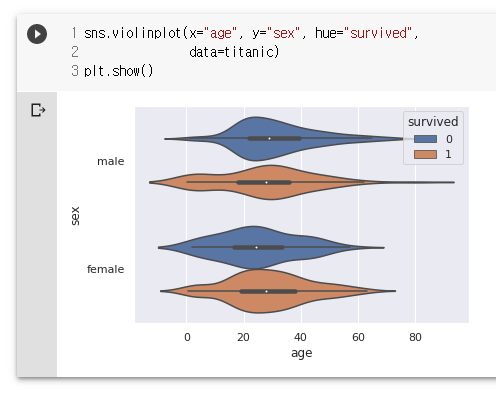
sns.violinplot(x="age", y="sex", hue="survived",
data=titanic)
plt.show()
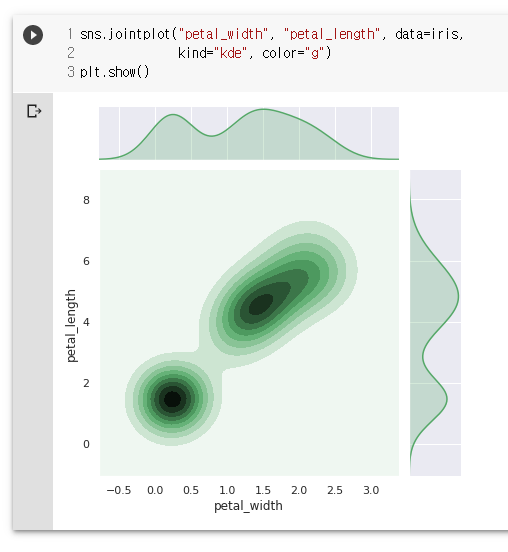
sns.jointplot("petal_width", "petal_length", data=iris,
kind="kde", color="g")
plt.show()
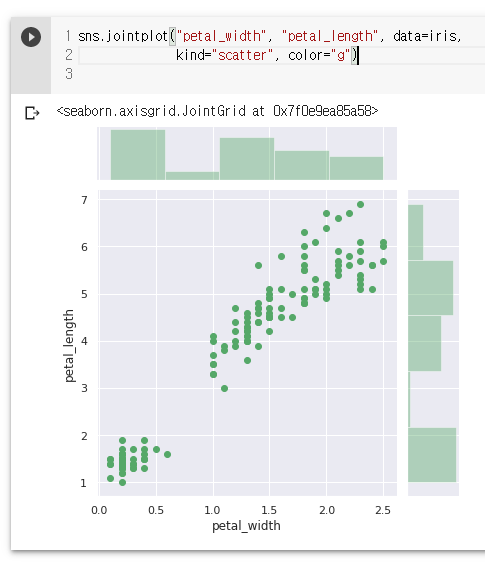
sns.jointplot("petal_width", "petal_length", data=iris,
kind="scatter", color="g")
plt.show()
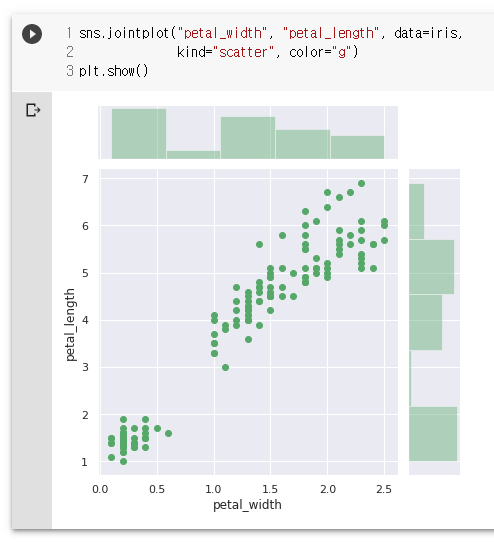
sns.jointplot("petal_width", "petal_length", data=iris,
kind="scatter", color="g")
g = sns.jointplot("petal_width", "petal_length", data=iris,
kind="scatter", color="g")
g.plot_joint(sns.kdeplot, color="c")
plt.show()

sns.pairplot(iris, hue="species", palette="husl",
markers=["o", "s", "D"])

import numpy as np
np.random.seed(0)
x = np.random.randn(100)
from scipy.stats import norm
sns.distplot(x, fit=norm, kde=False)
plt.show()

from scipy.stats import norm
sns.distplot(x, kde=False)
plt.show()
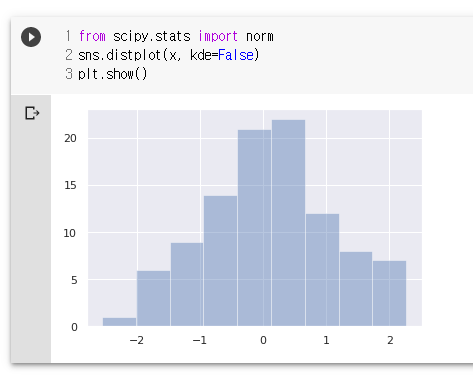
from scipy.stats import norm
sns.distplot(x, kde=True)
plt.show()

from scipy.stats import norm
sns.distplot(x, fit=norm, kde=True)
plt.show()

# Seaborn을 이용한 시각화 2/2
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
iris = sns.load_dataset("iris")
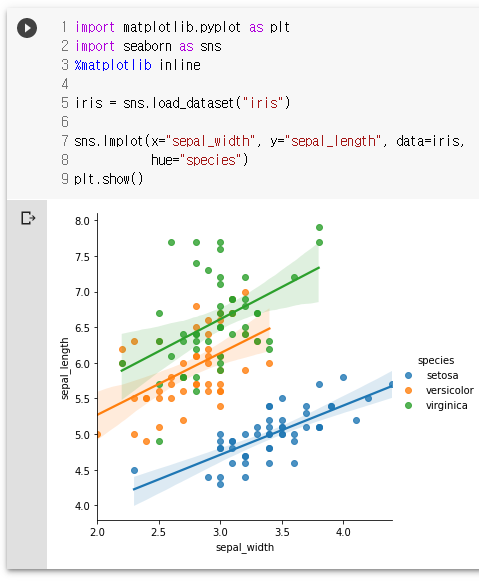
sns.lmplot(x="sepal_width", y="sepal_length", data=iris,
hue="species")
plt.show()
sns.lmplot(x="sepal_width", y="sepal_length", data=iris)

sns.regplot(x="sepal_width", y="sepal_length", data=iris)

sns.regplot(x="petal_length", y="petal_width", data=iris)

sns.clustermap(iris.iloc[:, :-1])
plt.show()

species = iris.pop("species")
iris.head()

sns.clustermap(iris)
plt.show()

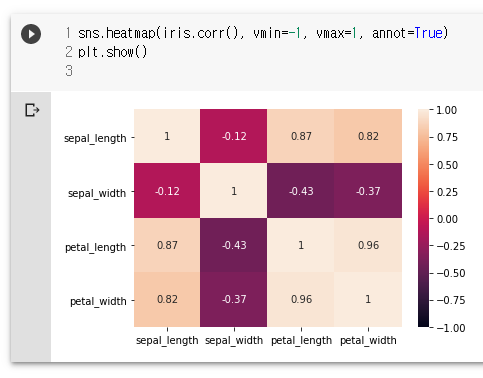
iris.corr() # iris 의 상관계수

sns.heatmap(iris.corr(), vmin=-1, vmax=1)
plt.show()

sns.heatmap(iris.corr(), vmin=-1, vmax=1, annot=True)
plt.show()
sns.heatmap(iris.corr(), vmin=-1, vmax=1, annot=True,
cmap="cool_r")
plt.show()

import numpy as np
mask = np.zeros_like(iris.corr())
mask
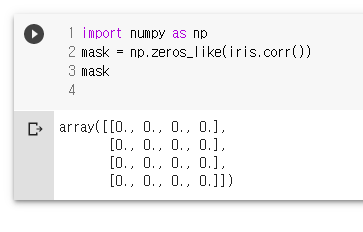
mask[np.triu_indices_from(mask)]
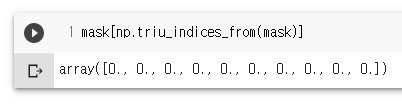
mask[np.triu_indices_from(mask)] = True
mask[np.triu_indices_from(mask)]

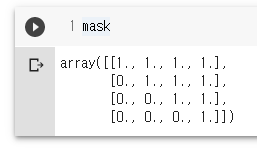
mask
with sns.axes_style("white"):
sns.heatmap(iris.corr(), mask=mask, square=True)
plt.show()

import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
%config InlineBackend.figure_format="retina"
iris=sns.load_dataset("iris")
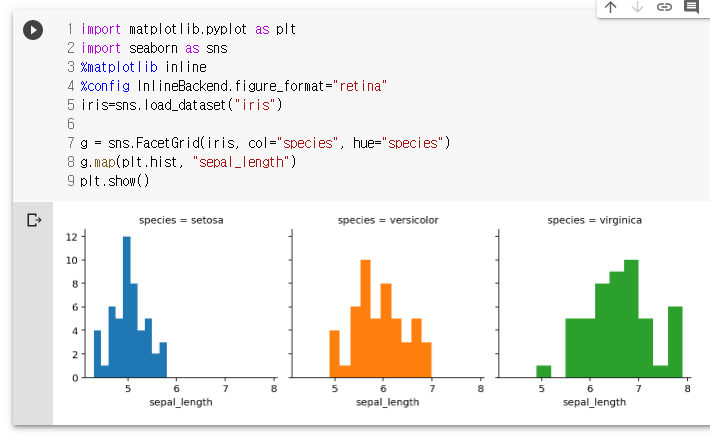
g = sns.FacetGrid(iris, col="species", hue="species")
g.map(plt.hist, "sepal_length")
plt.show()
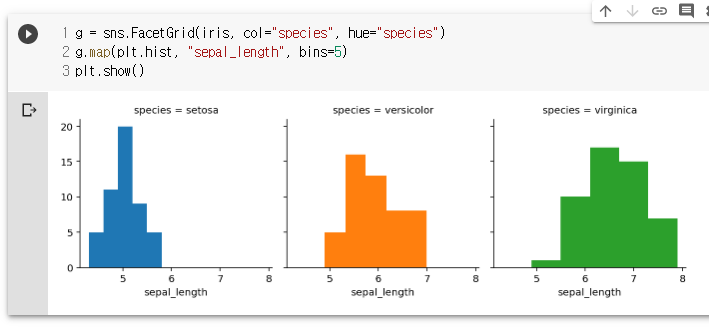
g = sns.FacetGrid(iris, col="species", hue="species")
g.map(plt.hist, "sepal_length", bins=5)
plt.show()
g = sns.FacetGrid(iris, col="species", hue="species")
g.map(plt.hist, "sepal_length", bins=5)
g.set_axis_labels("sepal_length", "Count")
plt.show()

g = sns.FacetGrid(iris, col="species", hue="species")
g.map(sns.scatterplot, "petal_width", "petal_length",
size=iris.sepal_length)
plt.show()

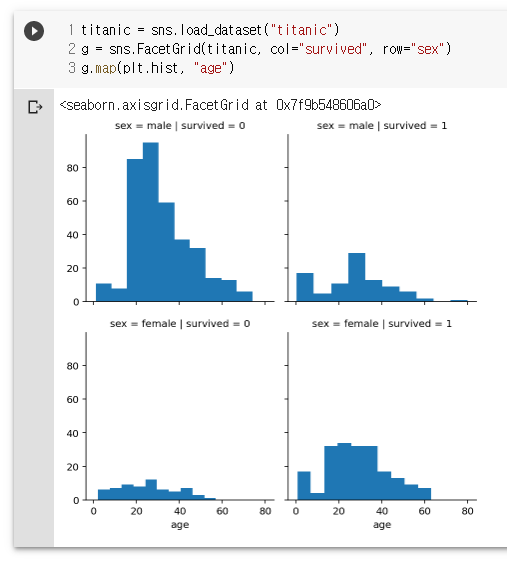
titanic = sns.load_dataset("titanic")
g = sns.FacetGrid(titanic, col="survived", row="sex")
g.map(plt.hist, "age")
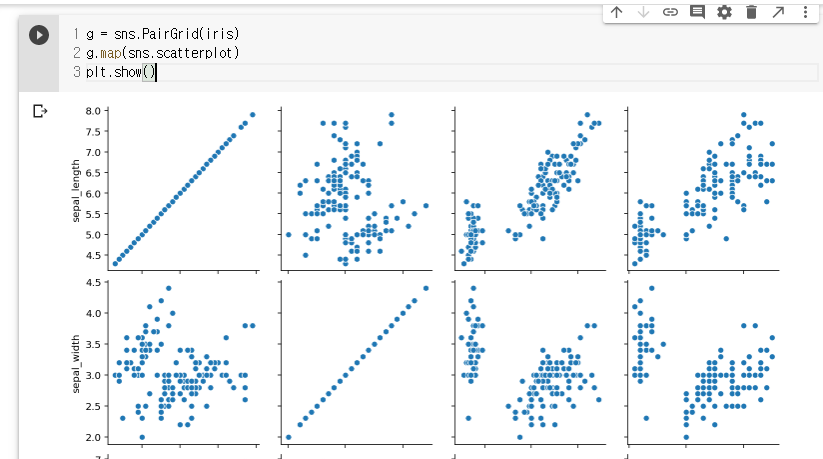
g = sns.PairGrid(iris)
g.map(sns.scatterplot)
plt.show()
g = sns.PairGrid(iris)
g.map_diag(sns.kdeplot)
g.map_lower(sns.scatterplot)
g.map_upper(sns.regplot)
plt.show()

g = sns.JointGrid(x="petal_length", y="petal_width",
data=iris)
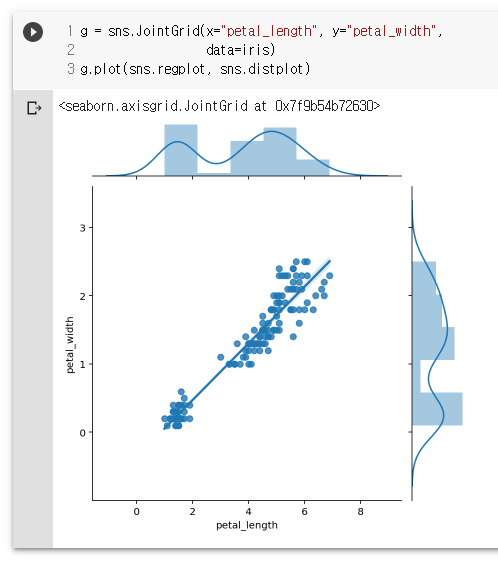
g.plot(sns.regplot, sns.distplot)
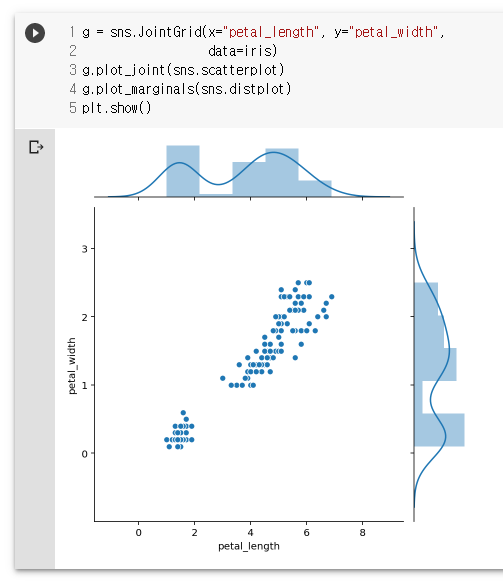
g = sns.JointGrid(x="petal_length", y="petal_width",
data=iris)
g.plot_joint(sns.scatterplot)
g.plot_marginals(sns.distplot)
plt.show()
# 뷰티풀솝과 파서
https://www.w3schools.com/css/default.asp
!pip install requests_file

from requests_file import FileAdapter
import requests
s = requests.Session()
s.mount("file://", FileAdapter())
res = s.get("file:///sample.html")
res

!pip install beautifulsoup4

from bs4 import BeautifulSoup
soup = BeautifulSoup(res.content, "html.parser")
soup

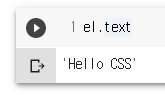
el = soup.select_one("h1")
el

el.text
div_el = soup.select("div")
div_el

soup.select_one("div")

soup.select("h1, span")

soup.select("div b")

soup

soup.select("div > b")

soup.select(".contents")

soup.select("div.contents")

soup.select("#subject")

soup.select("#subject")[0]

soup.select("[id=subject]")

https://www.w3schools.com/css/css_selectors.asp
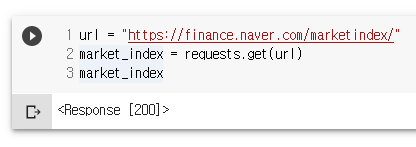
url = "https://finance.naver.com/marketindex/"
market_index = requests.get(url)
market_index
soup = BeautifulSoup(market_index.content, "html.parser")
price = soup.select_one("div.head_info > span.value")
price

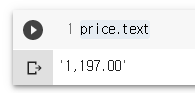
price.text
!pip install requests
import requests
requests.get("https://api.github.com")

response = requests.get("https://api.github.com")
response.content

response.status_code

response

if response.status_code == 200:
print("Success")
elif response.status_code == 404:
print("Not Found")

if response:
print("Success")
else:
print("Error")

print(response.content)

response.text

res = requests.get("http://javaspecialist.co.kr")
res.content

res.text

response.json()

response.headers

response.headers["Content-Type"]

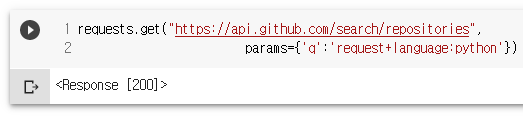
requests.get("https://api.github.com/search/repositories",
params={'q':'request+language:python'})
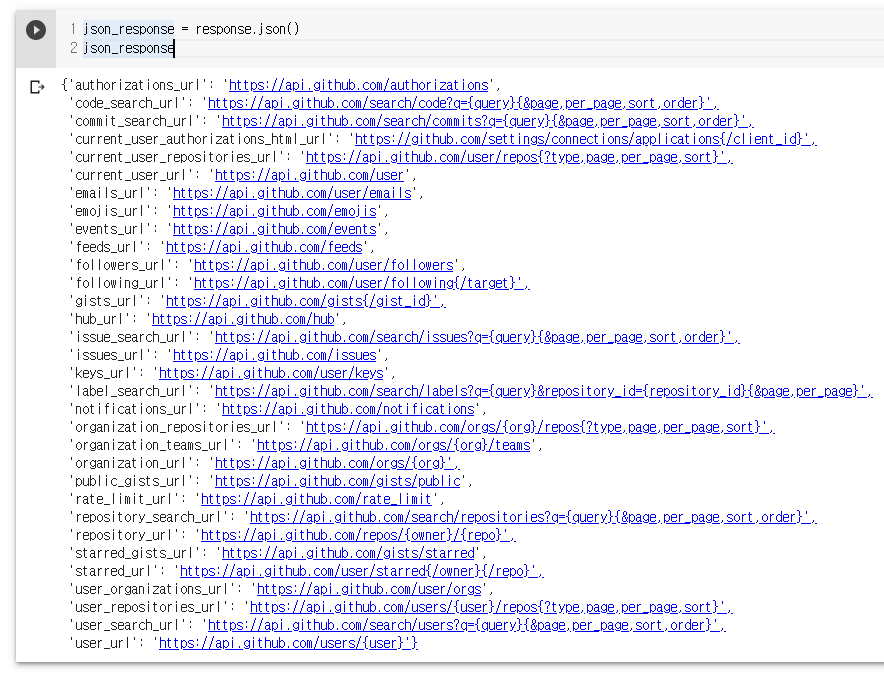
json_response = response.json()
json_response
response = requests.get(
"https://api.github.com/search/repositories",
params={'q':'request+language:python'},
headers={"Accept":"application/vnd.github.v3.text-match+json"})
response.json()

requests.post("https://httpbin.org/post",
data={"key":"value"})

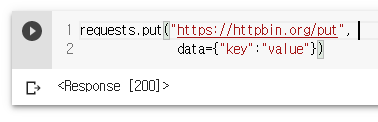
requests.put("https://httpbin.org/put",
data={"key":"value"})
requests.delete("https://httpbin.org/delete",
data={"key":"value"})

requests.head("https://httpbin.org/get")

requests.post("https://httpbin.org/post",
data={"key":"value"})

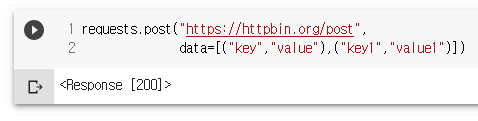
requests.post("https://httpbin.org/post",
data=[("key","value"),("key1","value1")])
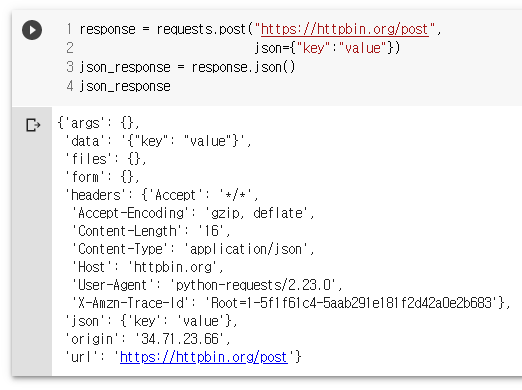
response = requests.post("https://httpbin.org/post",
json={"key":"value"})
json_response = response.json()
json_response
response.request.headers["content-Type"]

from getpass import getpass
requests.get("https://api.github.com/user",
auth=("id", getpass()))

requests.get("https://api.github.com", verify=False)

requests.get("https://api.github.com", timeout=1)
from requests.exceptions import Timeout
try :
response = requests.get("http://api.github.com",
timeout=1)
except Timeout:
print("요청 시간 초과")
else :
print("정상 처리")

with requests.Session() as session:
session.auth = ('id', getpass())
response = session.get("https://api.github.com/user")
print(response.headers)
print(response.json())

from requests.adapters import HTTPAdapter
from requests.exceptions import ConnectionError
github_adapter = HTTPAdapter(max_retries=3)
session = requests.Session()
session.mount("https://api.github.com", github_adapter)
try:
session.get("https://api.github.com")
except ConnectionError as ce:
print(ce)
# 텍스트 마이닝 개요
# 텍스트 전처리, 개수 기반 단어 표현, 문서 유사도, 토픽 모델링, 연관 분석, 딥러닝을 이용한 자연어 처리, 워드 임베딩, 텍스트 분류, 태깅, 번역
# NLTK 자연어처리 패키지
# corpus, tokenizing, morphological analysis, POS tagging
import nltk
nltk.download()

import nltk
nltk.download("treebank")

from nltk.corpus import treebank
print(treebank.fileids())

treebank.sents("wsj_0001.mrg")

wsj_0001 = treebank.sents("wsj_0001.mrg")
for line in wsj_0001:
print(' '.join(line))

treebank.tagged_words("wsj_0001.mrg")

print(treebank.parsed_sents("wsj_0001.mrg")[0])

nltk.download("book", quiet=True) # 로그출력 안함

from nltk.book import *

type(text1)
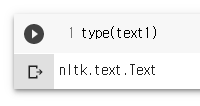
text1

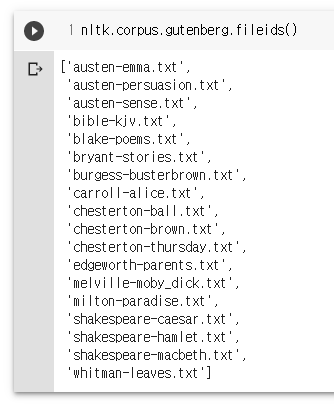
nltk.corpus.gutenberg.fileids()
emma = nltk.corpus.gutenberg.raw("austen-emma.txt")
print(emma[:200])

from nltk.tokenize import sent_tokenize
print(sent_tokenize(emma[:1000])[3])

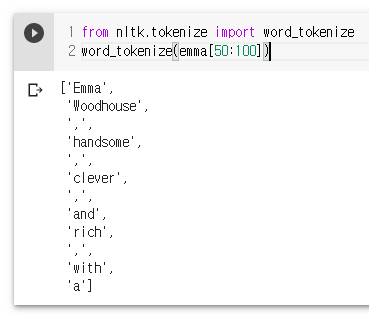
from nltk.tokenize import word_tokenize
word_tokenize(emma[50:100])
from nltk.tokenize import RegexpTokenizer
ret = RegexpTokenizer("[\w]+") # 1회 이상
ret.tokenize(emma[50:100])

# 어간추출
words = ["sending", "cooking", "files", "lives", "crying", "dying"]
from nltk.stem import PorterStemmer
pst = PorterStemmer()
pst.stem(words[0])

[pst.stem(w) for w in words]

from nltk.stem import LancasterStemmer
lst = LancasterStemmer()
[lst.stem(w) for w in words]

from nltk.stem.regexp import RegexpStemmer
rest = RegexpStemmer('ing')
[rest.stem(w) for w in words]

words2 = ['enviar','cocina','moscas', 'vidas','llorar','morir']
from nltk.stem.snowball import SnowballStemmer
sbst = SnowballStemmer('spanish')
[sbst.stem(w) for w in words2]

# 원형복원
words3 = ["cooking", "believes"]
from nltk.stem.wordnet import WordNetLemmatizer
wl = WordNetLemmatizer()
[wl.lemmatize(w) for w in words]

[wl.lemmatize(w, pos='v') for w in words3]

# 품사 태깅
nltk.help.upenn_tagset('NNP')

nltk.help.upenn_tagset()

sentense = emma[50:289]
print(sentense)

from nltk.tag import pos_tag
tagged_list = pos_tag(word_tokenize(sentense))
print(tagged_list)

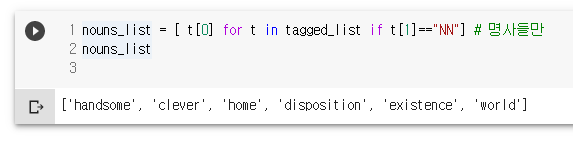
nouns_list = [ t[0] for t in tagged_list if t[1]=="NN"] # 명사들만
nouns_list
import re
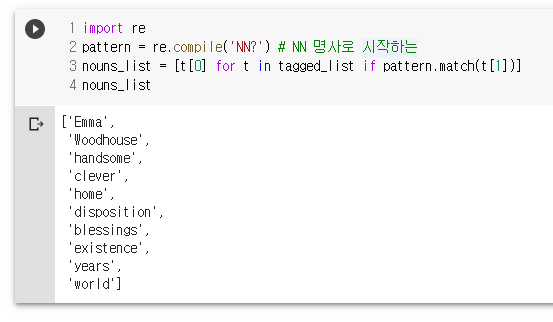
pattern = re.compile('NN?') # NN 명사로 시작하는
nouns_list = [t[0] for t in tagged_list if pattern.match(t[1])]
nouns_list
tagged_list

from nltk.tag import untag
untag(tagged_list)

["/".join(p) for p in tagged_list]

ret = RegexpTokenizer("[\w]{2,}")
from nltk import Text
emma_text = Text(ret.tokenize(emma))
emma_text.plot(20)

emma_text.concordance('Emma', lines=5)

emma_text.similar("general")

emma_text.similar("general", 10)

emma_text.common_contexts(["general","strong"])

emma_text.dispersion_plot(["Emma","Knightley","Frank","Jane","Harriet","Robert"])

len(emma_text) # 단어 개수

len(set(emma_text)) # 중복을 제거한 단어 개수

len(set(emma_text)) / len(emma_text) # 어휘 풍부성

emma_fd = emma_text.vocab()
type(emma_fd)
# emma 말뭉치에서 사람 이름을 가져와 품사 태그에서 단어 빈도 수
from nltk import FreqDist
stopwords = ["Mr.","Mrs","Miss","Mr","Mrs","Dear"] #불용어
emma_tokens = pos_tag(emma_text)
names_list = [ t[0] for t in emma_tokens
if t[1]=="NNP" and t[0] not in stopwords ]
emma_fd_names = FreqDist(names_list)
emma_fd_names

emma_fd_names.most_common(5)

# 한글 형태소 분석, 의미를 가진 최소 단위
# KoNLPy: Python용 자연어 처리기, http://konlpy.readthedocs.org, http://konlpy.org, https://github.com/konlpy/konlpy
# KOMORAN: 자바로 만든 형태소 분석기, https://shineware.tistory.com/tag/KOMORAN/
# HanNanum: 자바로 만든 형태소 분석기, http://semanticweb.kaist.ac.kr/home/index.php/HanNanum
# KoNLP: R용 자연어 처리기, https://github.com/haven-jeon/KoNLP
!pip install konlpy

# 품사 태그
# https://konlpy-ko.readthedocs.io/ko/v0.4.3/morph/#comparison-between-pos-tagging-classes
https://konlpy.org/en/latest/morph/#pos-tagging-with-konlpy
https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0
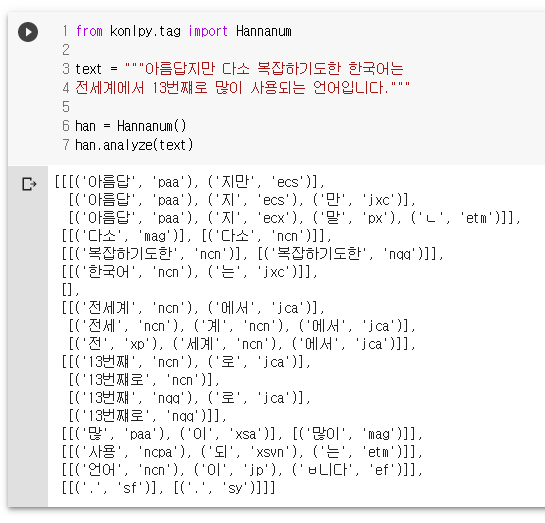
from konlpy.tag import Hannanum
text = """아름답지만 다소 복잡하기도한 한국어는
전세계에서 13번쨰로 많이 사용되는 언어입니다."""
han = Hannanum()
han.analyze(text)
han.morphs(text)

han.nouns(text)

han.pos(text)

han.pos(text, ntags=22) # 기본 9

from konlpy.tag import Kkma
Kkma = Kkma()
print(Kkma.morphs(text))

print(Kkma.nouns(text)) # 명사를 추출

print(Kkma.pos(text))

from konlpy.tag import Komoran
kom = Komoran()
kom.morphs(text)

print(kom.nouns(text)) # 명사만 추출

print(kom.pos(text))

from konlpy.corpus import kolaw
c = kolaw.open("constitution.txt").read()
print(c[:100])

from konlpy.corpus import kobill
d = kobill.open('1809890.txt').read()
print(d[150:300])

# 워드 클라우드
!pip install wordcloud

from konlpy.corpus import kolaw
data = kolaw.open("constitution.txt").read()
from konlpy.tag import Komoran
komoran = Komoran()
print(komoran.nouns("%r"%data[0:1000]))

word_list = komoran.nouns("%r"%data[0:1000])
text = ' '.join(word_list)
text

import matplotlib.pyplot as plt
%matplotlib inline
from wordcloud import WordCloud
wordc = WordCloud()
wordc.generate(text) # 문장

plt.imshow(wordc)
plt.show()
wordc = WordCloud(background_color="white", max_words=20,
relative_scaling=0.2,
font_path='/H2PORL.TTF')
wordc.generate(text)
plt.figure()
plt.imshow(wordc)
plt.axis("off")

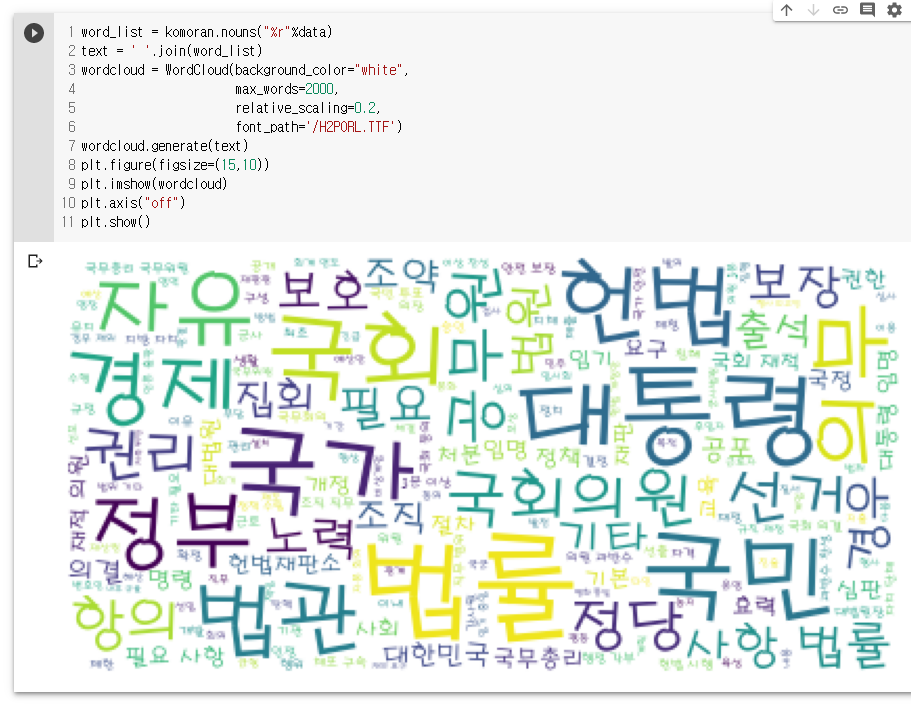
word_list = komoran.nouns("%r"%data)
text = ' '.join(word_list)
wordcloud = WordCloud(background_color="white",
max_words=2000,
relative_scaling=0.2,
font_path='/H2PORL.TTF')
wordcloud.generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
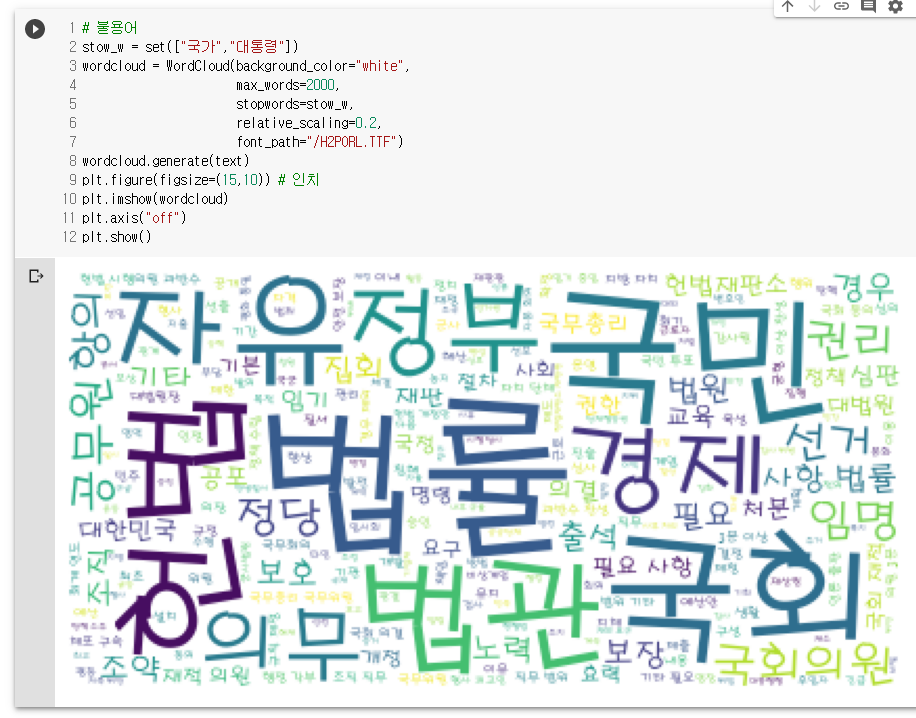
# 불용어
stow_w = set(["국가","대통령"])
wordcloud = WordCloud(background_color="white",
max_words=2000,
stopwords=stow_w,
relative_scaling=0.2,
font_path="/H2PORL.TTF")
wordcloud.generate(text)
plt.figure(figsize=(15,10)) # 인치
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
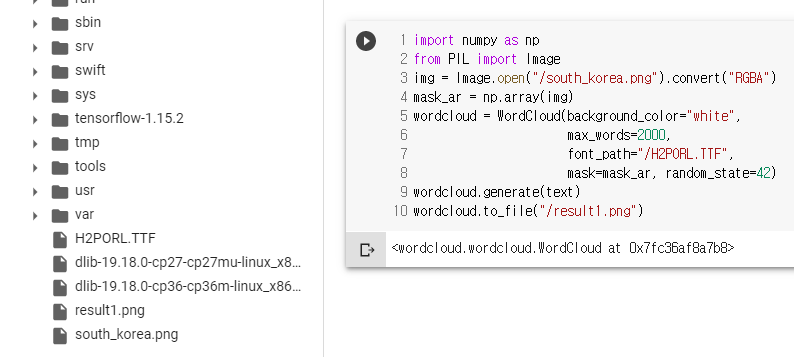
import numpy as np
from PIL import Image
img = Image.open("/south_korea.png").convert("RGBA")
mask_ar = np.array(img)
wordcloud = WordCloud(background_color="white",
max_words=2000,
font_path="/H2PORL.TTF",
mask=mask_ar, random_state=42)
wordcloud.generate(text)
wordcloud.to_file("/result1.png")

import random
def grey_color(*args, **kwargs):
return 'hsl(40, 100%%, %d%%)'% random.randint(50,100)
wordcloud.generate(text)
wordcloud.recolor(color_func=grey_color)
wordcloud.to_file("/result2.png")

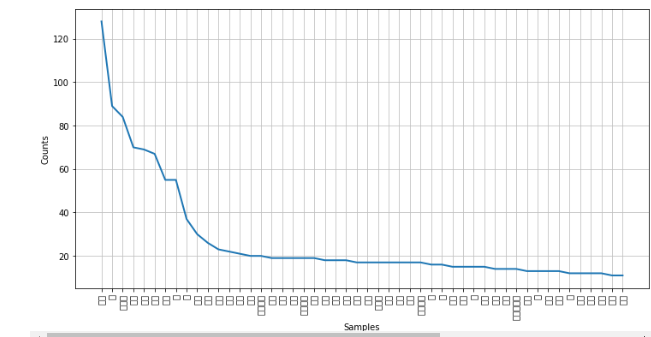
import nltk
import matplotlib.font_manager as fm
plt.figure(figsize=(12,6))
font_path = "/H2PORL.TTF"
font_name = fm.FontProperties(fname=font_path).get_name()
plt.rc("font", family=font_name)
nltk.Text(word_list).plot(50)
'푸닥거리' 카테고리의 다른 글
| IIS에서 apk 파일 다운로드 가능하도록 설정 (0) | 2020.09.14 |
|---|---|
| 딥러닝을 활용한 이미지 처리 (0) | 2020.08.08 |
| 딥러닝을 활용한 자연어 처리 (1) | 2020.07.04 |
| 가용성 다단계 웹 테스트 등록 (0) | 2020.07.03 |
| hash-based message authentication code (0) | 2020.02.24 |



댓글