#프라이빗 #GPT #모델 #만들기 #OpenAI #LLM #LangChain #LIamaIndex
- 자동화를 위한 일관된 답 얻기와 데이터 처리 방법
- 인식 모델과 생성 모델의 차이와 딥러닝 모델의 한계
- 자동화를 위한 컴플릿리과 체의 차이와 펑션 정의, 임베딩의 의미
- 임베딩의 개념과 활용
- 모델 평가 방법과 객관적 평가 방법
- 버전 관리와 업그레이드의 중요성
- 인공지능 트랜스포머와 메모리 세팅의 차이
- 챗봇 개발과 위키피디아 임베딩
- 데이터 중복 제거와 API 사용의 필요성
- 라마 인덱스와 데이터 처리 기능 제공
- 오픈 ai와 코드 대문자화의 필요성
- sa를 통한 질문과 유용성
- 인덱스와 랭크를 이용한 상장회사 공시 보고서 검색
- 인공지능 모델의 전문성과 범형성
- 생성형 ai를 활용한 새로운 방법의 전달
CAPABILITIES
- Text generation
- Function calling
- Embeddings
- Fine-tuning
- Image generation
- Vision
- Text-to-speech
- Speech-to-text
- Moderation
https://gptforwork.com/tools/openai-api-and-other-llm-apis-response-time-tracker

The 3 charts below track the response times of the main large language model APIs: OpenAI and Azure OpenAI (GPT-4, GPT-3.5, GPT-3), Anthropic Claude and Google PaLM.
gptforwork.com

Incidents Uptime ← Current Status Powered by Atlassian Statuspage
status.openai.com

Derive insights from images with AutoML Vision, or use pre-trained Vision API models or create computer vision applications with Vertex AI Vision
cloud.google.com
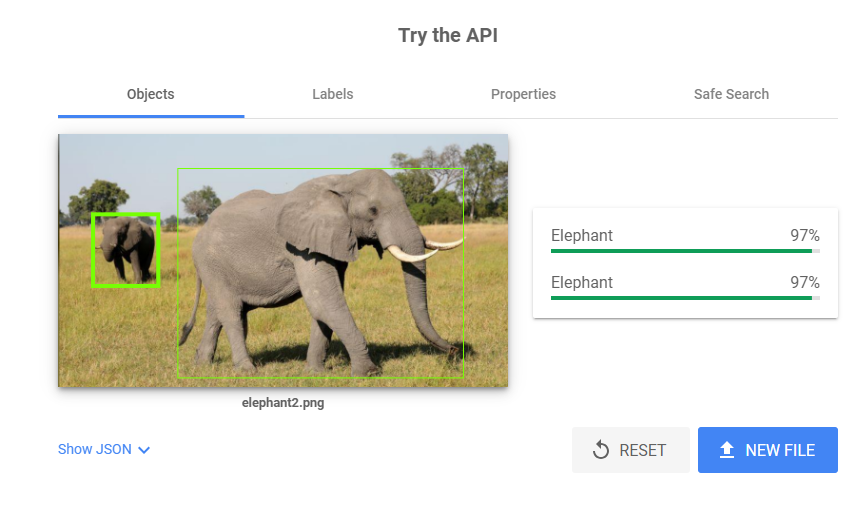
인식모델은 케익을 가방으로 인식
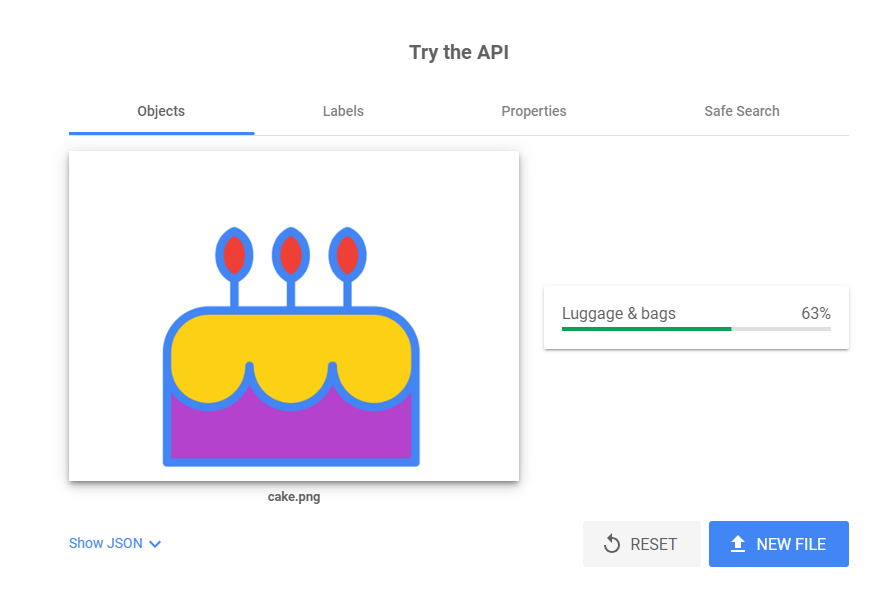
스포츠 중계 방송 자동화 등


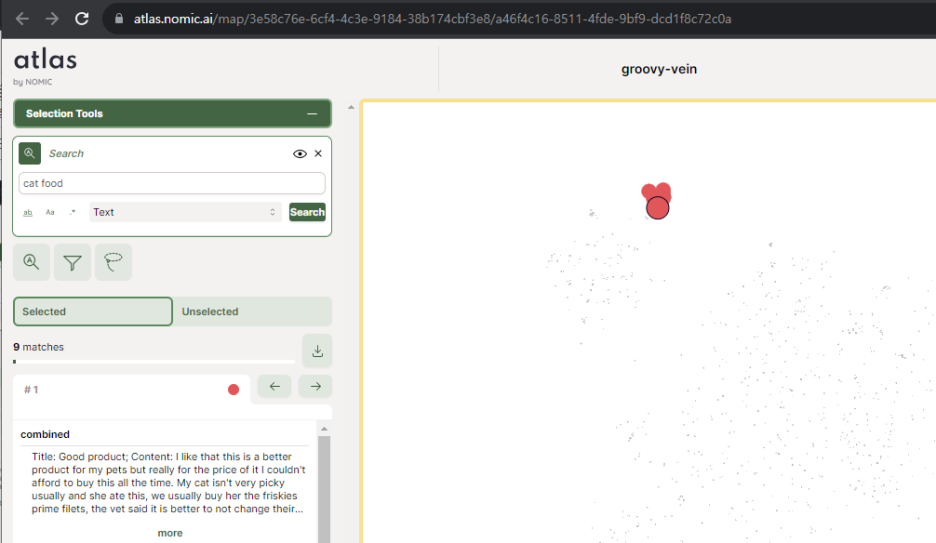
Structure unstructured datasets of text, images, embeddings, audio and video.
atlas.nomic.ai

Function calling

- Function calling
- Embeddings
- Fine-tuning

- Fine-tuning
RAG applications can use the LlamaIndex query interface for accessing that data and powering LLMs
LlamaIndex vs LangChain
Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt

%%capture
!pip install openai==0.28
!pip install datasets!pip show openai | grep Versionimport os
import getpass
import openai
openai.api_key = getpass.getpass(prompt = 'OpenAI API')dataset = {
"train": [
{
"instruction": " ",
"output": " "
},
{
"instruction": " ",
"output": " "
}
]
}
import json
list_message = []
num_data = len(dataset["train"]) # 데이터셋의 길이를 사용
for i in range(num_data):
instruction = dataset["train"][i]["instruction"]
output = dataset["train"][i]["output"]
print("질문:", instruction)
print("답변:", output)
message = [
{"role": "user", "content": instruction},
{"role": "assistant", "content": output},
]
list_message.append(message)
with open("output1.jsonl", "w") as file:
for messages in list_message:
json_line = json.dumps({"messages": messages})
file.write(json_line + '\n')
upload_file = openai.File.create(
file=open("output1.jsonl", "rb"),
purpose='fine-tune'
)import openai
openai.api_key = 'sk-' # Replace with your actual API key
try:
upload_file = openai.File.retrieve("file-O0eEwlZRoFvDANDKqBatdExq")
print(upload_file)
except openai.error.InvalidRequestError as e:
print("Error occurred:", e)
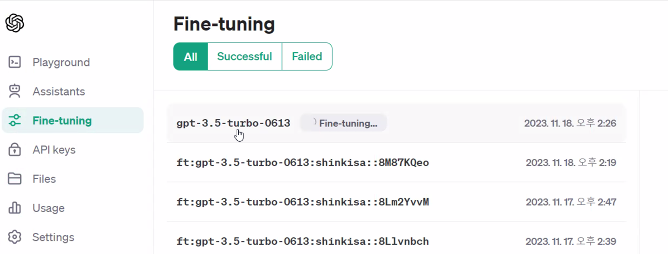
start_train = openai.FineTuningJob.create(training_file=upload_file["id"],model="gpt-3.5-turbo")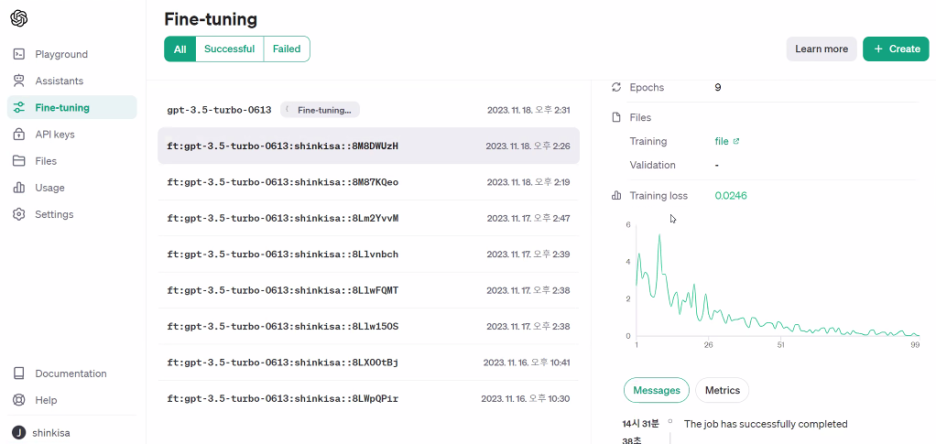

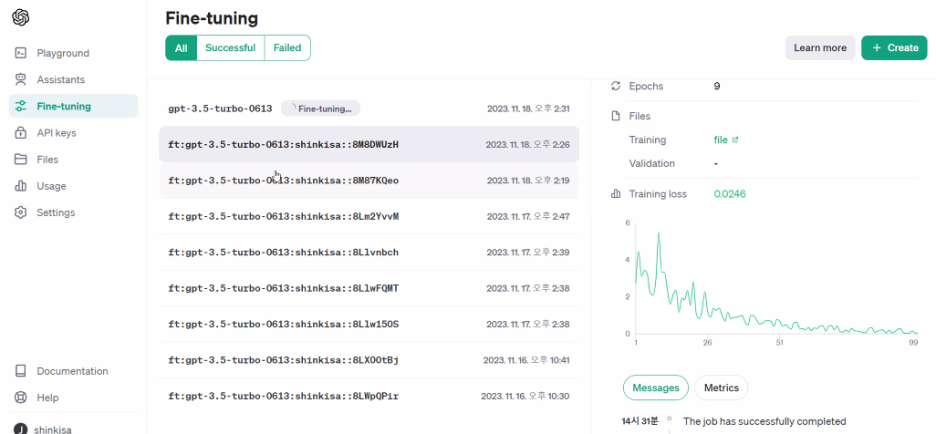
# Fine-tuning 작업 상태 확인
status = openai.FineTuningJob.list(limit=10)
status["data"][0]# 모델 이름 얻기
fine_tuned_model = status["data"][1]["fine_tuned_model"]
print(fine_tuned_model)completion = openai.ChatCompletion.create(
model=status["data"][1]["fine_tuned_model"],
messages=[
{"role": "user", "content": ""}
]
)print(completion.choices[0].message["content"])completion = openai.ChatCompletion.create(
model=status["data"][1]["fine_tuned_model"],
messages=[
{"role": "user", "content": "Python의 @에 대한 설명"}
]
)
completion = openai.ChatCompletion.create(
model=status["data"][1]["fine_tuned_model"],
messages=[
{"role": "user", "content": "라면 끓일때 가장 중요한 것은?"}
]
)print(completion.choices[0].message["content"])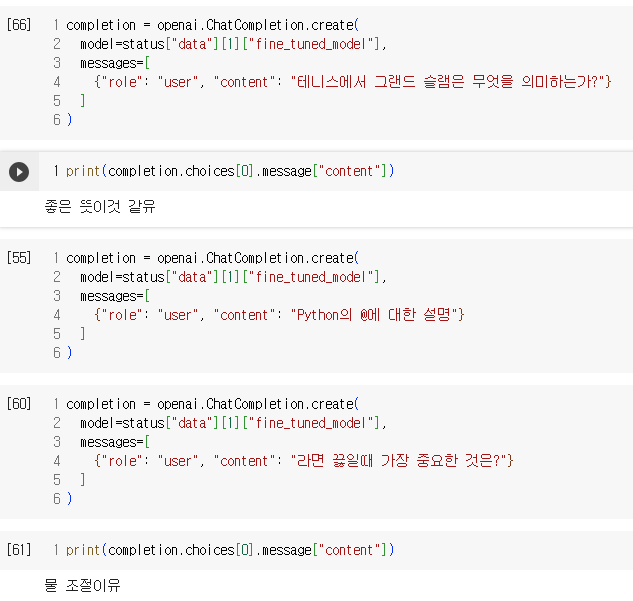
- Fine-tuning 파인튜닝

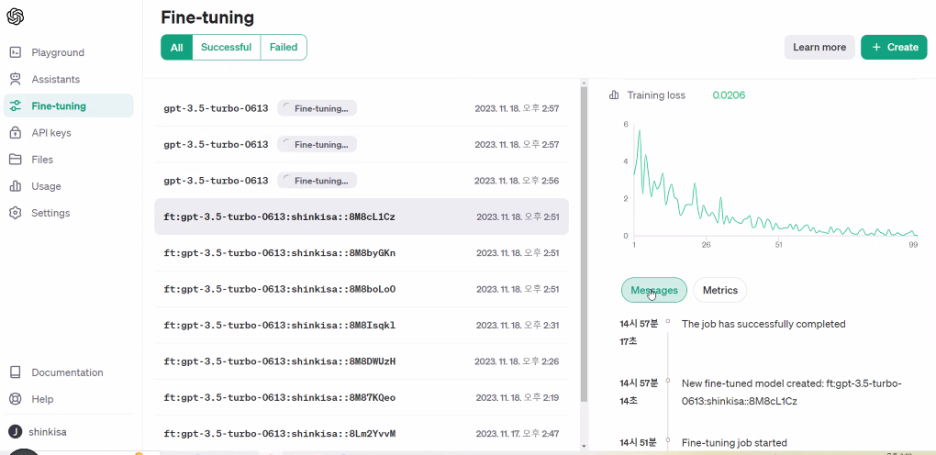
- Pretraining 프리트레이닝 모델
LangChain
파이썬 문서: https://python.langchain.com/en/latest/index.html
개념 문서: https://docs.langchain.com/docs/
소스: https://github.com/hwchase17/langchain
#@title 기본 패키지(openai, langchain) 설치
!pip install openai==0.28
!pip install langchain
#@title 기타 패키지 설치 (구글검색, 위키피디아, VectorStore, HuggingFace Embedding)
!pip install google-search-results
!pip install wikipedia
!pip install faiss-cpu # 오픈소스 벡터DB (Facebook, MIT license)
!pip install sentence_transformers # HuggingFace Embedding 사용 위해서 필요
!pip install tiktoken # Summarization 할때 필요
#@title 0. API 키 설정
import os
#@markdown https://platform.openai.com/account/api-keys
OPENAI_API_KEY = "sk-" #@param {type:"string"}
#@markdown https://huggingface.co/settings/tokens
#@markdown HuggingFace에서 모델 다운로드나 클라우드 모델 사용하기 위해서 필요 (무료)
HUGGINGFACEHUB_API_TOKEN = "hf_" #@param {type:"string"}
#@markdown https://serpapi.com/manage-api-key
#@markdown 구글 검색하기 위해서 필요 (월 100회 무료)
SERPAPI_API_KEY = "" #@param {type:"string"}
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
os.environ["SERPAPI_API_KEY"] = SERPAPI_API_KEY
#@title 1. OpenAI LLM (text-davinci-003)
from langchain.llms import OpenAI
#@title 1. OpenAI LLM (text-davinci-003)
from langchain.llms import OpenAI
llm = OpenAI(model_name='text-davinci-003', temperature=0.9)
langchain.llms.openai.OpenAI
llm('미국의 빌보드차트에 오른 한국 가수 이름을 알려 주세요.')
llm('2020 올림픽은 어디에서 개최 되었나요?')
#@title 2. ChatOpenAI LLM (gpt-3.5-turbo)
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0.9)
sys = SystemMessage(content="당신은 스포츠 전문 AI입니다.")
msg = HumanMessage(content='2020 하계 올림픽에서 대한민국 금메달 획득 갯수는?')
aimsg = chat([sys, msg])
aimsg.content
#@title 3. Prompt Template & chain
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["상품"],
template="{상품} 만드는 회사 이름 추천해줘. 기억에 남는 한글 이름으로",
)
prompt.format(상품="신발")
from langchain.chains import LLMChain
chain = LLMChain(llm=chat, prompt=prompt)
# chain.run("AI 여행 추천 서비스")
chain.run(상품="콜라")
#@title 4. ChatPromptTemplate & chain
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
chat = ChatOpenAI(temperature=0)
template="You are a helpful assisstant that tranlates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chatchain = LLMChain(llm=chat, prompt=chat_prompt)
chatchain.run(input_language="English", output_language="Korean", text="Thanks god TGIF!")
#@title 5. Agents and Tools
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
tools = load_tools(["serpapi", "llm-math"], llm=chat)
# tools = load_tools(["wikipedia", "llm-math"], llm=chat)
agent = initialize_agent(tools, llm=chat, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("한국의 'New Jeans' 그룹 멤버의 인원 수는? 오늘 2023년 11월 17일 현재 전체 멤버들의 나이의 합은?") # 한국의 'New Jeans' 그룹 멤버의 인원 수는? 오늘 2023년 5월 30일 현재 전체 멤버들의 나이의 합은 얼마인가요
len(agent.tools)
print(agent.tools[0].description)
print(agent.tools[1].description)
#@title 6. Memory
from langchain import ConversationChain
conversation = ConversationChain(llm=chat, verbose=True)
conversation.predict(input="인공지능에서 Transformer가 뭐야?")
conversation.predict(input="RNN하고 차이 설명해줘.")
conversation.predict(input="Seq2Seq 와도 차이점을 비교해줘.")
conversation.memory
#@title 7. Document Loaders
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_path="https://ko.wikipedia.org/wiki/NewJeans")
documents = loader.load()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
len(docs)
# 4096 token = 3000 English word
print(docs[-1].page_content)
#@title 8. Summarization
from langchain.chains.summarize import load_summarize_chain
chain = load_summarize_chain(chat, chain_type="map_reduce", verbose=True)
chain.run(docs[:-1])
#@title 9. Embeddings and VectorStore
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.embeddings import OpenAIEmbeddings
# embeddings = OpenAIEmbeddings()
embeddings = HuggingFaceEmbeddings()
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import FAISS
# from langchain.text_splitter import RecursiveCharacterTextSplitter
# text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
index = VectorstoreIndexCreator(
vectorstore_cls=FAISS,
embedding=embeddings,
# text_splitter=text_splitter,
).from_loaders([loader])
# 파일로 저장
index.vectorstore.save_local("faiss-nj")
index.query("뉴진스의 데뷔곡은?", llm=chat, verbose=True)
index.query("뉴진스의 데뷔 멤버는?", llm=chat, verbose=True)
index.query("멤버의 나이는?", llm=chat, verbose=True)
index.query("멤버의 나이는? (오늘은 2023년 11월 18일)", llm=chat, verbose=True)
#@title FAISS 벡터DB 디스크에서 불러오기
from langchain.indexes.vectorstore import VectorStoreIndexWrapper
fdb = FAISS.load_local("faiss-nj", embeddings)
index2 = VectorStoreIndexWrapper(vectorstore=fdb)
index2.query("뉴진스의 데뷔 멤버는?", llm=chat, verbose=True)



Memory
- ConversationBufferMemory : 대화 기록(기본)
- ConversationBufferWindowMemory : 마지막 n개의 대화만 기억
- Entity Memory : 개체에 대한 정보를 저장
- Conversation Knowledge Graph Memory: 개체의 triple 저장: (sam, 좋아하는 색, 파랑)
- ConversationSummaryMemory : 대화의 요약본을 저장
- ConversationSummaryBufferMemory : 대화 요약본 + 마지막 n토큰 기억
- ConversationTokenBufferMemory : 마지막 n토큰 기억
- VectorStore-Backed Memory : 벡터DB에 정보 저장
LIamaIndex vs Langchain

LangChain’s flexible abstractions and extensive toolkit unlocks developers to build context-aware, reasoning LLM applications.
www.langchain.com
!pip install --upgrade openai
!pip show openai | grep Version
!pip install llama-index pypdf
!pip install langchain
import openai
# Set up the OpenAI API client
openai.api_key = "sk-"
import os
openai_api_key = os.getenv('OPENAI_API_KEY', 'sk-')
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from langchain.agents import Tool
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent
from llama_index import VectorStoreIndex, SimpleDirectoryReader
!mkdir data
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents=documents)
tools = [
Tool(
name="LlamaIndex",
func=lambda q: str(index.as_query_engine().query(q)),
description="useful for when you want to answer questions about the author. The input to this tool should be a complete english sentence.",
return_direct=True,
),
]
# set Logging to DEBUG for more detailed outputs
memory = ConversationBufferMemory(memory_key="chat_history")
llm = ChatOpenAI(temperature=0, openai_api_key='sk-')
agent_executor = initialize_agent(
tools, llm, agent="conversational-react-description", memory=memory
)
agent_executor.run(input="hi, i am bob")
agent_executor.run(input="What did the author do growing up?")
# try using SummaryIndex!
from langchain.llms import OpenAI
from langchain.llms import OpenAIChat
from langchain.agents import initialize_agent
from llama_index import SummaryIndex
from llama_index.langchain_helpers.memory_wrapper import GPTIndexChatMemory
index = SummaryIndex([])
# set Logging to DEBUG for more detailed outputs
# NOTE: you can also use a conversational chain
memory = GPTIndexChatMemory(
index=index,
memory_key="chat_history",
query_kwargs={"response_mode": "compact"},
# return_source returns source nodes instead of querying index
return_source=True,
# return_messages returns context in message format
return_messages=True,
)
# llm = OpenAIChat(temperature=0)
llm=OpenAI(temperature=0, openai_api_key='sk-')
agent_executor = initialize_agent(
[], llm, agent="conversational-react-description", memory=memory
)
agent_executor.run(input="hi, i am bob")
# NOTE: the query now calls the SummaryIndex memory module.
agent_executor.run(input="what's my name?")
!pip install --upgrade openai
!pip install llama-index pypdf
!pip install python-dotenv
# Environment Variables
import os
from dotenv import load_dotenv
openai_api_key = os.getenv('OPENAI_API_KEY', 'sk-')
import openai
# Set up the OpenAI API client
openai.api_key = "sk-"
# OpenAI_key = os.environ.get("OPENAI_API_KEY")
# print(OpenAI_key)
# OPENAI_API_KEY="sk-"
# openai.api_key=OPENAI_API_KEY
from langchain import OpenAI
from llama_index import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
from llama_index import set_global_service_context
from llama_index.response.pprint_utils import pprint_response
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.query_engine import SubQuestionQueryEngine
# llm = OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=-1)
llm = OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=-1, openai_api_key="sk-")
service_context = ServiceContext.from_defaults(llm=llm)
set_global_service_context(service_context=service_context)
lyft_docs = SimpleDirectoryReader(input_files=["S-ECOPRO-20230814.pdf"]).load_data()
uber_docs = SimpleDirectoryReader(input_files=["S-INTERROJO-20230814.pdf"]).load_data()
print(f'Loaded lyft 10-K with {len(lyft_docs)} pages')
print(f'Loaded Uber 10-K with {len(uber_docs)} pages')
lyft_index = VectorStoreIndex.from_documents(lyft_docs)
uber_index = VectorStoreIndex.from_documents(uber_docs)
lyft_engine = lyft_index.as_query_engine(similarity_top_k=3)
uber_engine = uber_index.as_query_engine(similarity_top_k=3)
response = await lyft_engine.aquery('What is the summay of company in 2023?')
print(response)
response = await uber_engine.aquery('What is the summary of company in 2021?')
print(response)
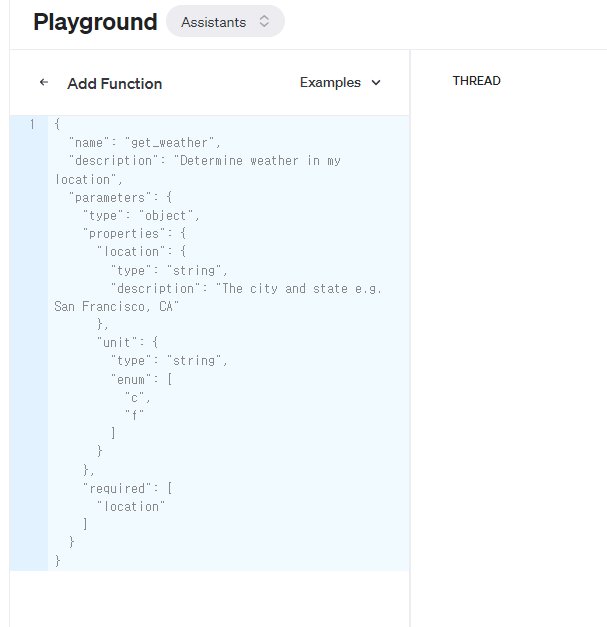
Assistants -> function


'푸닥거리' 카테고리의 다른 글
| Apache Workers: 로드 밸런싱과 AJP 프로토콜 (0) | 2025.01.19 |
|---|---|
| 딥러닝 모델 구현 (0) | 2024.12.22 |
| 스프링에서 데코레이터 패턴 구현하기 (0) | 2023.11.04 |
| Apache Tomcat, Java, Spring Framework 환경에서 Application Insights를 적용하는 방법 (0) | 2023.10.21 |
| cpu와 gpu 그리고 npu (0) | 2023.10.14 |




댓글